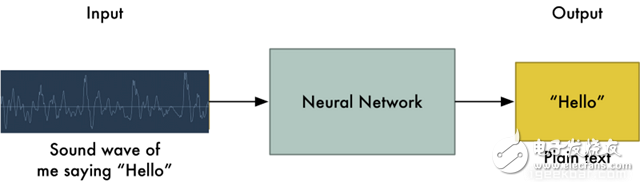
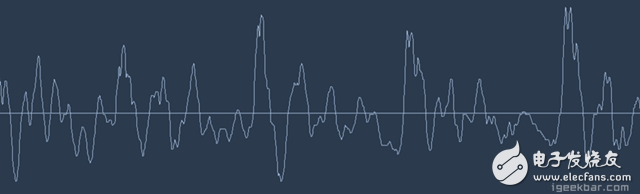
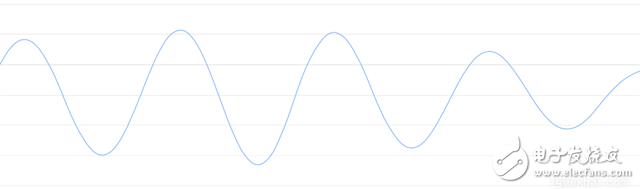
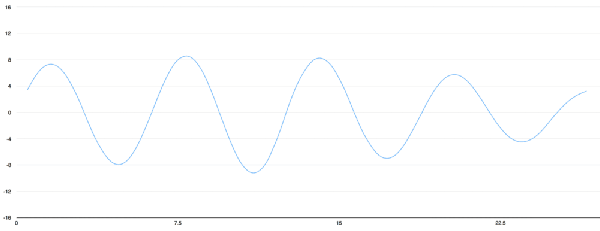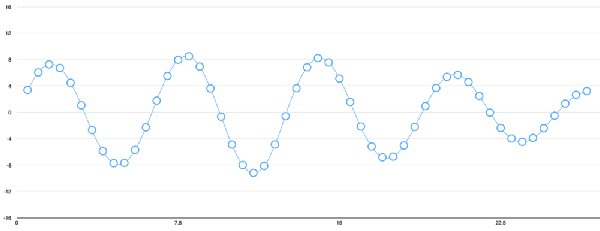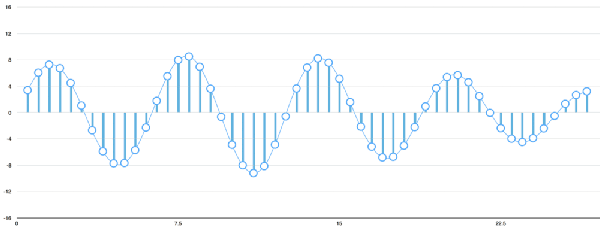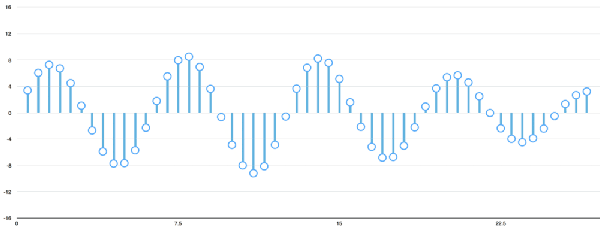
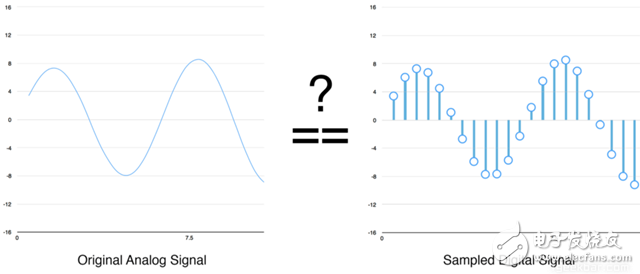
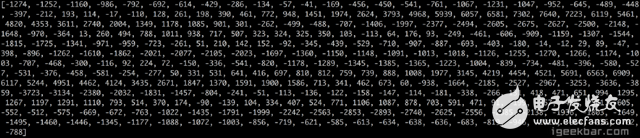
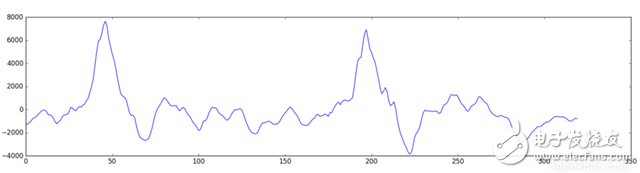
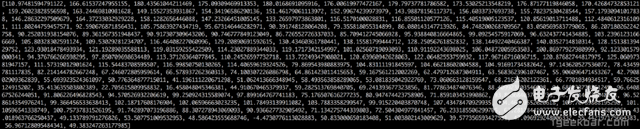
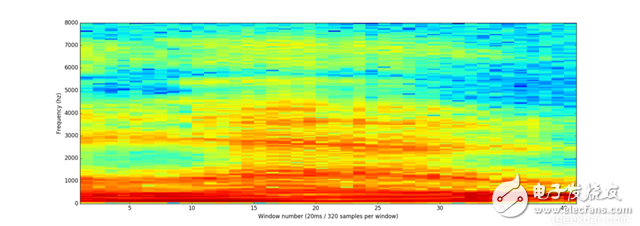
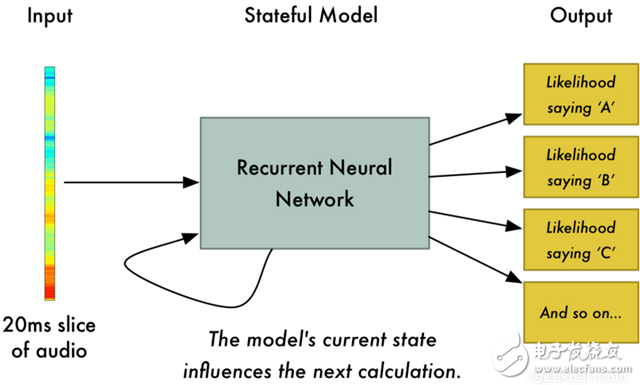
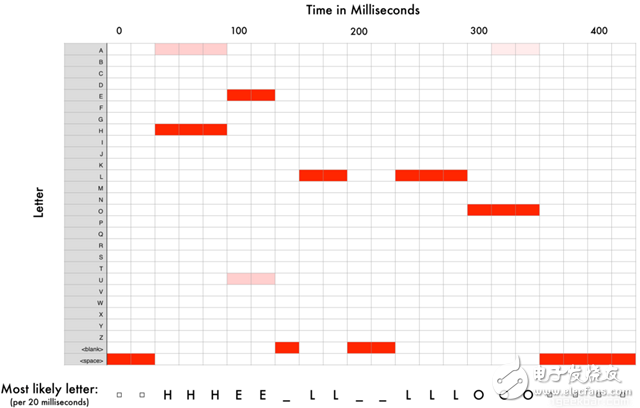
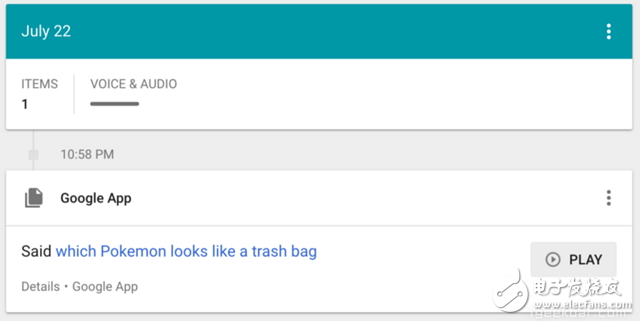
Speech recognition is "invading" our lives. Speech recognition is built into our mobile phones, game consoles and smart watches. He is even automating our house. For just $50, you can buy an Amazon Echo Dot, a magic box that lets you order takeaways, listen to weather forecasts, and even buy garbage bags, all you need to say is: Aleax, give me a pizza! Echo Dot became popular on the Christmas holiday of 2015 and sold out immediately on Amazon. But in fact, speech recognition has been around for many years, so why is it now mainstream? Because depth recognition finally improves the accuracy of speech recognition in an uncontrolled environment to a level that is practical enough. Professor Wu Enda has predicted that when the accuracy of speech recognition increases from 95% to 99%, it will become the primary way to interact with computers. Let's learn and deep learning for speech room recognition. If you want to know how neural machine translation works, you should guess that we can simply send some sounds to the neural network and then train it to generate text: This is the highest pursuit of deep learning using speech recognition, but unfortunately we have not done this completely yet (at least not when I wrote this article – I bet, we can do it in a few years) To) A big problem is that the speed of speech is different. One person may say "Hello!" very quickly, while another person may say "heeeelllllllllllloooooo!" very slowly, resulting in a sound file with more data and longer. Both files should be Recognized as the same text – “Hello! It turns out that it is very difficult to automatically align audio files of various lengths into a fixed length of text. In order to solve this problem, we must use some special techniques and perform some special processing outside the deep neural network. Let's see how it works! Obviously, the first step in speech recognition is – we need to input sound waves into the computer. How should we convert sound waves into numbers? Let's use the sound clip "hello" that I am talking about as an example: Sound waves are one-dimensional, and each time there is a value based on its height. Let's take a look at a small part of the sound wave: In order to convert this sound wave into a number, we only record the height of the sound wave at the equidistant point: This is called sampling. We read thousands of times per second and recorded the sound wave at a height of that point in time. This is basically an uncompressed .wav audio file. The “CD quality†audio is sampled at 44.1khz (44100 readings per second). But for speech recognition, the sampling rate of 16khz (16,000 samples per second) is enough to cover the frequency range of human speech. Let's sample the "Hello" sound wave 16,000 times per second. This is the first 100 samples: Each number represents the amplitude of the sound wave at one of 16,000 points in one second. Because sonic sampling is only an intermittent reading, you might think that it is only a rough approximation of the original sound wave. There is a gap between our readings, so we will lose data, right? However, because of the sampling theorem (Nyquist theorem), we know that we can use mathematics to perfectly reconstruct the original sound waves from the spaced samples—as long as our sampling frequency is at least twice as fast as the highest expected frequency. I mention this because almost everyone makes this mistake and mistakes that using a higher sampling rate will always result in better audio quality. Actually not. We now have a series of numbers, each of which represents a sound wave amplitude of 1/16,000 seconds. We can enter these numbers into the neural network, but trying to directly analyze these samples for speech recognition is still difficult. Instead, we can make the problem easier by doing some pre-processing of the audio data. Let's get started, first divide our sampled audio into 20-millisecond audio blocks. This is our first 20 millisecond audio (ie our first 320 samples): Drawing these numbers as simple line graphs, we get the approximate shape of the original sound waves in these 20 milliseconds: Although this recording is only 1/50 second in length, even such a short recording is complicated by sounds of different frequencies. There are some bass, some midrange, and even a few highs. But in general, it is these sounds of different frequencies that are mixed together to form the human voice. In order to make this data more easily processed by the neural network, we will break this complex sound wave into components. We will separate the bass part, then separate the next lowest part, and so on. Then add (from low to high) the energy in each frequency band and we create a fingerprint for each category of audio clip. Imagine you have a recording of someone playing C major chords on the piano. This sound is a combination of three notes: C, E, and G. They are mixed together to form a complex sound. We want to resolve this complex sound into separate notes to distinguish between C, E, and G. This is the same as speech recognition. We need a Fourier Transform to do this. It breaks down complex sound waves into simple sound waves. Once we have these separate sound waves, we add together the energy contained in each band. The end result is the importance of each frequency range from bass (ie bass notes) to treble. With a frequency of 50hz per unit, the energy contained in our 20ms audio can be expressed as the following list from low frequency to high frequency: But it's easier to understand when drawing them as charts: As you can see, there are a lot of low frequency energy in our 20 millisecond sound clip, but there is not much energy at higher frequencies. This is the typical "male" voice. If we repeat this process for each 20-millisecond audio block, we will end up with a spectrogram (each column from left to right is a 29-millisecond audio block) The spectrogram is cool because you can actually see notes and other pitch patterns in the audio data. For neural networks, it is much easier to find patterns from such data than the original sound waves. So this is how we will actually enter the neural network into the neural network. Now that we've turned the audio into an easy-to-handle format, we're going to enter it into a deep neural network. The input to the neural network will be a 20 millisecond audio block. For each small audio slice, the neural network will try to find the letter corresponding to the sound that is currently being spoken. We will use a circular neural network—a neural network with memory that can influence future predictions. This is because each letter it predicts should be able to influence its prediction of the next letter. For example, if we have said "HEL" so far, chances are that we will say "LO" to complete "Hello". It is unlikely that we will say something like "XYZ" that we can't read at all. Therefore, having previously predicted memory helps the neural network to make more accurate predictions for the future. After running our entire audio clip (one block at a time) through the neural network, we will end up with a mapping that identifies each audio block and its most likely letter. This is the general pattern of the mapping that I said "Hello": Our neural network is predicting that the word I am talking about is most likely "HHHEE_LL_LLLOOO". But it also thinks that what I said may also be "HHHUU_LL_LLLOOO" or even "AAAUU_LL_LLLOOO". We can follow some steps to organize this output. First, we will replace any duplicate characters with a single character: HHHEE_LL_LLLOOO becomes HE_L_LO HHHUU_LL_LLLOOO becomes HU_L_LO AAAUU_LL_LLLOOO becomes AU_L_LO Then we will remove all whitespace: HE_L_LO becomes HELLO HU_L_LO becomes HULLO AU_L_LO becomes AULLO This gives us three possible transliterations - "Hello", "Hullo" and "Aullo". If you say these words out loud, all these sounds are similar to "Hello." Because the neural network predicts only one character at a time, it will produce some transliteration that expresses the pronunciation. For example, if you say "He would not go", it might give a "He wud net go" transfer. The trick to solving the problem is to combine these pronunciation-based predictions with likelihood scores based on large databases of written text (books, news articles, etc.). Throw away the most unlikely results and leave the most practical results. In our possible transliteration of "Hello", "Hullo" and "Aullo", it is clear that "Hello" will appear more frequently in the text database (not to mention in our original audio-based training data), so It may be a positive solution. So we will choose "Hello" as our final result, not other transliteration. Get it! Wait a moment! You might think "but what if someone says Hullo"? This word does exist. Maybe "Hello" is the wrong transfer! Of course, some people may actually say "Hullo" instead of "Hello." However, such a speech recognition system (based on American English training) basically does not produce a transfer result such as "Hullo". The user says "Hullo", it always thinks that you are saying "Hello", no matter how many times you make a "U" sound. Give it a try! If your phone is set to American English, try to have your cell phone assistant recognize the word "Hullo". This is not ok! It doesn't work on the table, it always understands "Hello." Not recognizing "Hullo" is a reasonable behavior, but sometimes you will encounter an annoying situation: your phone just can't understand the valid statement you said. This is why these speech recognition models are always in a retraining state, and they need more data to fix these few situations. One of the coolest things about machine learning is that it sometimes looks very simple. You get a bunch of data, enter it into the machine learning algorithm, and then magically get a world-class AI system running on your game card... right? This is true in some cases, but not for speech recognition. Speech recognition is a difficult problem. You have to overcome almost endless challenges: poor quality microphones, background noise, reverb and echo, accent differences, and more. Your training data needs to cover everything, to ensure that the neural network can handle them. Here's another example: You know, when you talk in a noisy room, you will unconsciously raise your tone to cover the noise. Humans can understand you under what circumstances, but neural networks need training to deal with this special situation. So you need training data that people speak loudly in the noise! To build one that can be in Siri, Google Now! Or a speech recognition system running on a platform such as Alexa, you will need a lot of training data. If you don't hire hundreds of people to record for you, it requires much more training data than you can get. Since users have low tolerance for low-quality speech recognition systems, you can't be embarrassed. No one wants a voice recognition system that is only 80% effective. For companies like Google or Amazon, the tens of thousands of hours of vocal voice recorded in real life is gold. This is where the gap between their world-class speech recognition systems and your own systems. Let you use Google Now for free! Or Siri, or the $50 purchase of Alexa without a subscription fee means: let you use them as much as possible. Every sentence you say about these systems will be recorded forever and used as training data for future versions of speech recognition algorithms. This is their true purpose! do not trust me? If you have a Google Now installed! For Android phones, please click here to listen to every word you have said to it: You can find the same thing on Amazon via Alexa. However, unfortunately, Apple does not let you access your Siri voice data. So if you're looking for a startup idea, I don't recommend trying to build your own speech recognition system to compete with Google. Instead, you should think of a way for people to give you a few hours of recordings. This data can be your product.
ZGAR MINI
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
From production to packaging, the whole system of tracking, efficient and orderly process, achieving daily efficient output. We pay attention to the details of each process control. The first class dust-free production workshop has passed the GMP food and drug production standard certification, ensuring quality and safety. We choose the products with a traceability system, which can not only effectively track and trace all kinds of data, but also ensure good product quality.
We offer best price, high quality Vape Device, E-Cigarette Vape Pen, Disposable Device Vape,Vape Pen Atomizer, Electronic cigarette to all over the world.
Much Better Vaping Experience!
ZGAR Vape Pen,Disposable Device Vape Pen,UK ZGAR MINI Wholesale,ZGAR MINI Disposable E-Cigarette OEM Vape Pen,ODM/OEM electronic cigarette,ZGAR Mini Device ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.szdisposable-vape.com