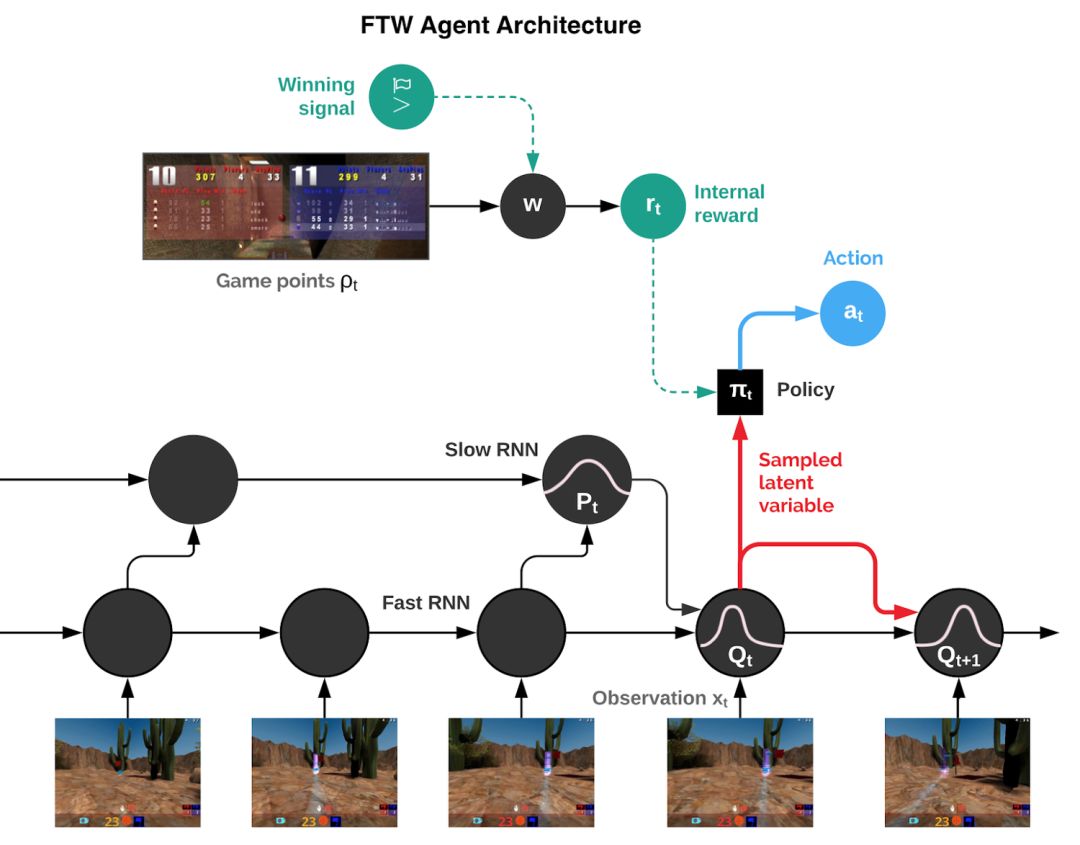
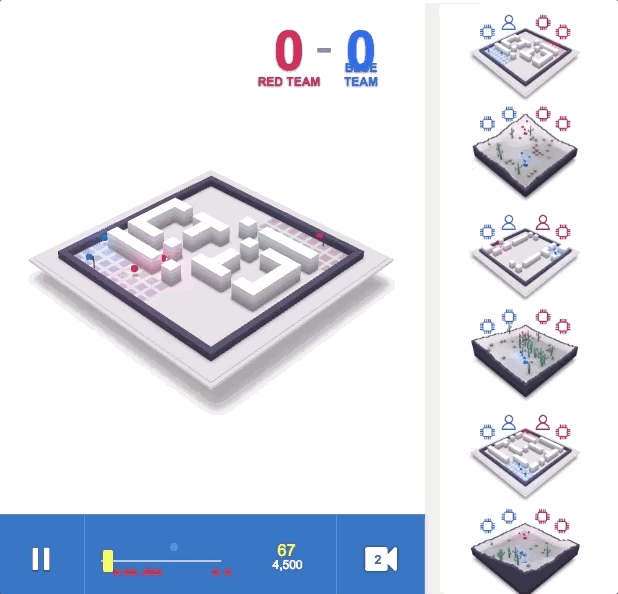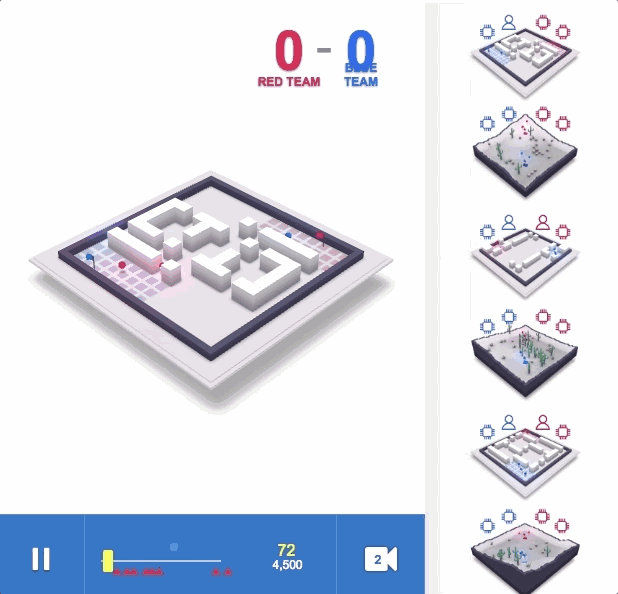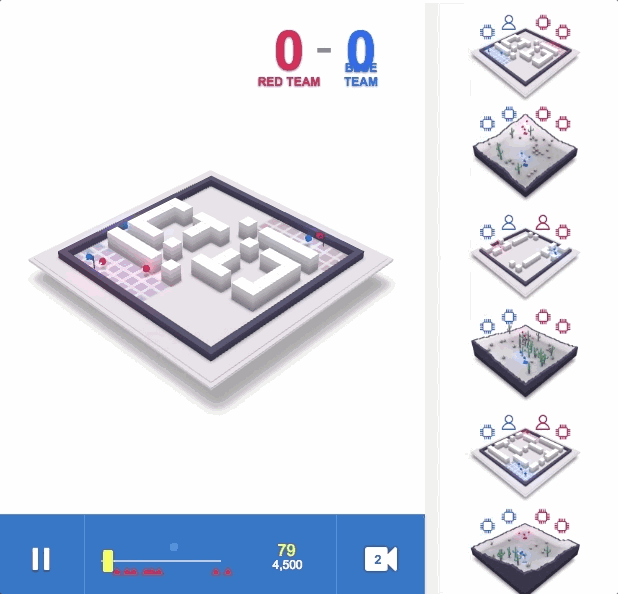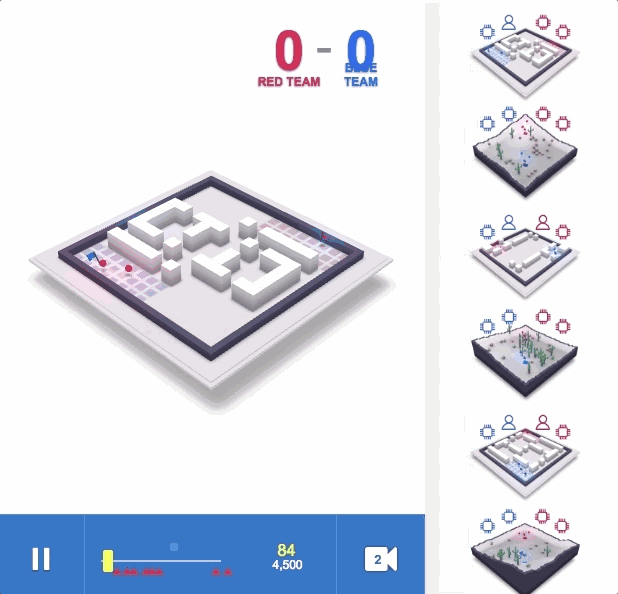
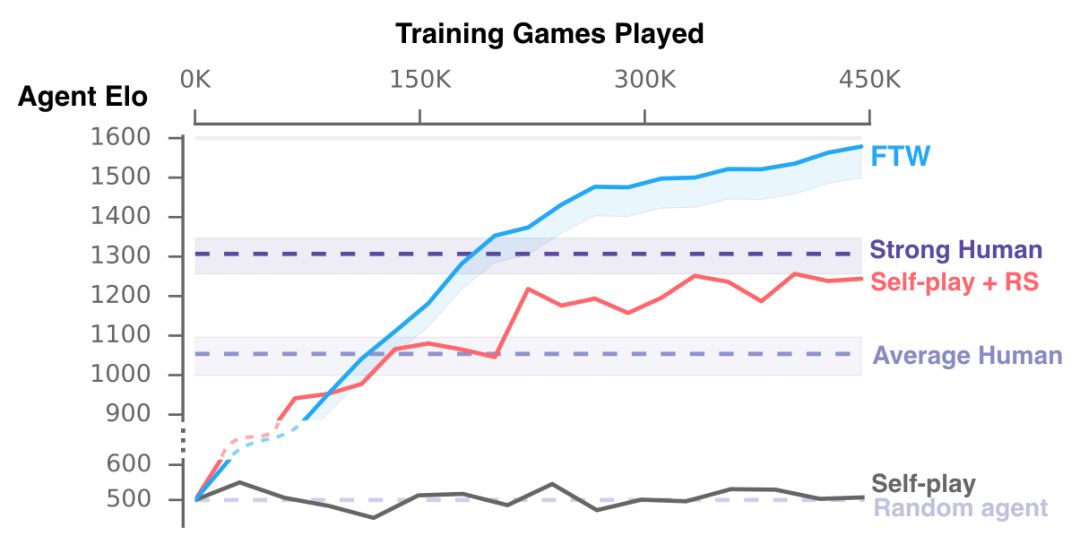
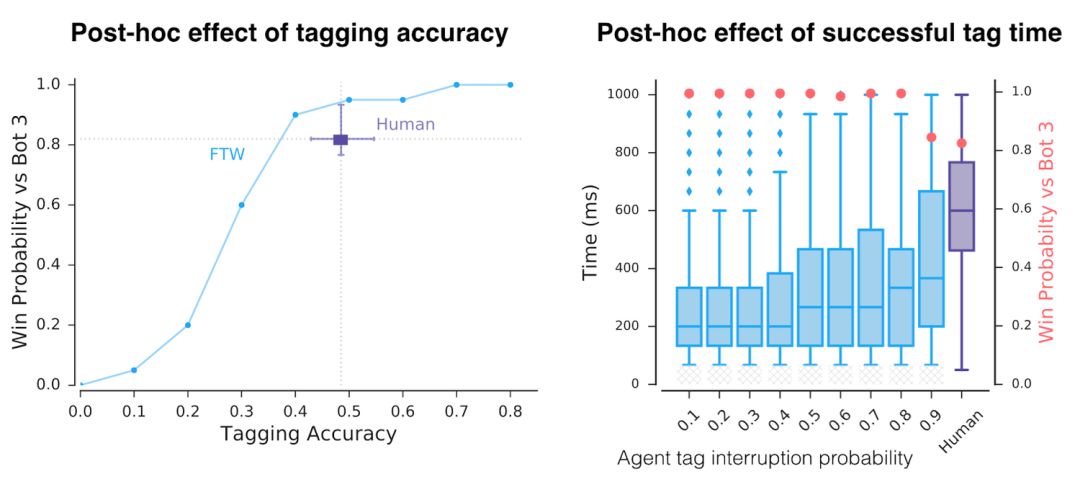
Following OpenAI, DeepMind is also showing its muscles in multi-agent reinforcement learning: for the first time, it beat humans in the multiplayer mode of a first-person shooter game, and it easily surpassed humans without using a large number of training rounds. Not long after OpenAI announced its victory over human players in 5v5 DOTA 2, today, DeepMind also shared their progress in multi-agent learning. CEO Hassabis shared on Twitter: "Our latest work shows that agents reach human levels in complex first-person multiplayer games and can also cooperate with human players!" The game Hassbis said is "Quaker III Arena", which is also the originator of many modern first-person shooter games. Players fight independently or in teams on the map, and respawn somewhere on the map within seconds after death. When one party reaches the victory condition (in DeepMind's experiment, it is to grab more flags), or the game lasts for a certain period of time, the round is declared to be over. The victory conditions depend on the selected game mode. Although Hassbis said on Twitter that their AI "reached the human level", in fact, from the experimental results, their AI has surpassed humans: when they played against a team of 40 human players, the pure AI team won. A purely human team (at an average of 16 flags), and has a 95% chance of defeating a team composed of AI and humans. This AI is called "For the Win" (FTW). It only played nearly 450,000 games and understood how to effectively cooperate and compete with people and other machines. The only restriction that researchers have on AI is to get as many flags as possible in 5 minutes. The game map for the battle is randomly generated and changes every game, and the indoor and outdoor terrain is different. When forming a team, the AI ​​may team up with people or team up with other AIs. The battle mode is divided into slow and high speed. During the training process, the AI ​​developed its own reward mechanism and learned strategies such as base defense, trailing teammates, or attacking outside the enemy camp. DeepMind wrote in their blog post today that from the perspective of multi-agents, playing a multiplayer video game like "Thor’s Hammer III" requires cooperation with teammates, competition with the enemy, and resistance to encounters. Maintain robustness in any battle style/strategy. The analysis found that in the game, AI is more efficient than humans in "tagging" (touching the opponent and returning it to the initial location on the map), and can succeed in 80% of the cases (48% for humans). What's more interesting is that after surveying the human players participating in the battle, it is found that everyone generally believes that AI is a better team player and better at cooperation. A major breakthrough in the first-person shooter multiplayer mode Wang Xiangjun, chief algorithm officer of Qiyuan World and former Netflix senior algorithm expert, told Xinzhiyuan: Previous first-person shooter (FPS) game research was mostly single-player mode. This time DeepMind has made a major breakthrough in FPS multiplayer mode, surpassing human level without using a large number of training rounds. Compared with the previous OpenAI Five, DeepMind's Capture the Flag (CTF) model directly learns from pixel, without feature engineering and separate training model for each agent, thanks to the following innovations: The application of Population-based training proposed by DeepMind Max Jaderberg last year has greatly improved training efficiency and provided diversified explorations to help the model adapt to different terrain teammate environments. The experimental results show better results than self-play. More efficient. For The Win agent's hierarchical reward mechanism to solve the credit assignment problem. Use fast and slow RNN and memory mechanism to achieve a function similar to Hierarchical RL. However, FPS is still much less difficult in strategy learning than Dota and Interstellar RTS games. The effect of the CTF model on long-term strategy games remains to be seen. In addition to the human battle mode, the CTF model also has a good effect on human-machine collaboration. It is worth mentioning that Qiyuan World released the StarCraft 2 Human-Computer Collaboration Challenge during the Peking University ACM Finals in April this year, and its intelligent body is also the first to have the ability to collaborate with humans and AI teams. Human-machine collaboration will become a very important part of the artificial intelligence research field in the future. Master strategy, understand tactics and teamwork Mastering strategy, tactical understanding, and teamwork in multiplayer video games are key challenges for artificial intelligence research. Now, thanks to the new progress made in reinforcement learning, our agent has reached human level performance in the "Quake III Arena" game, which is a classic 3D first-person multiplayer game. It is also a complex multi-agent environment. These agents exhibit the ability to simultaneously cooperate with artificial agents and human players. There are billions of people on the planet we live in. Everyone has his own personal goals and actions, but we are still able to unite through teams, organizations, and society to show significant collective wisdom. This is what we call multi-agent learning: many individual agents must be able to act independently, while also learning to interact and cooperate with other agents. This is an extremely difficult problem-because with co-adaptive agents, the world is constantly changing. To study this issue, we chose a 3D first-person multiplayer video game. These games are the most popular genre of video games and have attracted millions of players due to their immersive game design and their challenges in strategy, tactics, hand-eye coordination, and teamwork. The challenge for our agent is to learn directly from the original pixels to generate operations. This complexity makes first-person multiplayer games a very active research field in the artificial intelligence community and many results have been obtained. The game that our work focuses on is "Quaker III Arena" (we made some art changes to it, but all game mechanics remain the same). "Thor's Hammer III Arena" laid the foundation for many modern first-person video games, and has attracted a long-standing competitive e-sports scene. We train agents to learn and act as individuals, but they must be able to fight other agents or humans as a team. The CTF (Capture The Flag) game rules are very simple, but the dynamics are very complicated. In Quake 3, divide into blue and red teams to compete on a given map. The purpose of the competition is to bring back the opponent's flag and touch our flag that has not been moved. Our team will get a point, which is called a capture. In order to gain a tactical advantage, they can touch local players (tagging) and send them back to their turf. The team that captures the most flags within five minutes wins. FTW Agent: The level score far exceeds the baseline method and human players To make things more interesting, we designed a variant of CTF to change the layout of the map in every game. In this way, our agent is forced to adopt general strategies instead of remembering the layout of the map. In addition, in order to make the game more fair, agents have to experience the world of CTF in a way similar to humans: they observe a series of pixel images and issue actions through simulated game controllers. CTF is executed in the environment generated by the program, therefore, the agent must adapt to the invisible map. Agents must learn from the beginning how to observe, act, cooperate, and compete in an unseen environment, all of which come from a reinforcing signal in each game: whether their team wins. This is a challenging learning problem, and its solution is based on three general ideas of reinforcement learning: We are not training an agent, but a group of agents. They learn by playing games in teams, providing a variety of teammates and opponents. Each agent in the group learns its own internal reward signals, which enable the agent to generate its own internal goals, such as capturing a flag. The double optimization process can directly optimize the internal reward of the agent for winning, and use the reinforcement learning of the internal reward to learn the agent's strategy. Agents operate on two time scales, fast and slow, which improves their ability to use memory and generate consistent action sequences. Figure: Schematic diagram of For The Win (FTW) agent architecture. The agent combines fast and slow time scale cyclic neural networks (RNN), includes a shared memory module, and learns the conversion from game points to internal rewards. The resulting agent, which we call For The Win (FTW) agent, has learned to play CTF with a very high standard. Most importantly, the learned agent strategy is robust to the size of the map, the number of teammates, and other participants in the team. The following demonstrates an outdoor program environment game where FTW agents compete with each other, and an indoor program environment game where humans and agents compete. Figure: Interactive CTF game browser, with indoor and outdoor program generation environments. Outdoor map games are competitions between FTW agents, and indoor map games are competitions between humans and FTW agents (see icon). We hosted a game with 40 human players. In the game, humans and agents are paired randomly-either as rivals or as teammates. An early test game in which humans and trained agents play CTF together. The FTW agent learns to be stronger than the powerful baseline method and exceeds the win rate of human players. In fact, in a survey of participants, they were considered more cooperative than human participants. The performance of our agent during training. Our new FTW agent has achieved a higher Elo rating than human players and the baseline methods of Self-play + RS and Self-play-the probability of winning is also higher. In addition to performance evaluation, it is important to understand the behavior of these agents and the complexity of their internal representations. In order to understand how the agent represents the game state, we studied the activation mode of the agent's neural network drawn on a plane. The dots in the figure below indicate the situation during the game, and the nearby dots indicate similar activation patterns. These points are colored according to the state of the advanced CTF game. In these states, the agent has to ask itself: Which room is the agent in? What is the status of the flag? Which teammates and opponents can you see? We observe clusters of the same color, indicating that the agent expresses similar advanced game states in a similar way. How the agent represents the game world. Different situations conceptually correspond to the same game situation and are similarly represented by the agent. The trained agent even displays some artificial neurons, which directly encode specific situations. The agent has never been told the rules of the game, but it can learn basic game concepts and can effectively establish CTF intuition. In fact, we can find some specific neurons that can directly encode some of the most important game states, such as neurons that are activated when the agent’s flag is taken away, or activated when its teammates grab the opponent’s flag Of neurons. We further analyzed the use of memory and visual attention by agents in the paper. In addition to this rich representation, how else can the agent act? First, we noticed that the reaction time of these agents is very fast and tagging is also very accurate, which can be explained by their performance. However, by artificially reducing the accuracy and reaction time of tagging, we found that this is only one of the factors for their success. After training, the tagging accuracy and tagging reaction time of the agent are artificially reduced. Even with the accuracy and response time comparable to humans, the performance of the agent is still higher than that of humans. Through unsupervised learning, we established prototypical behaviours of the agent and humans, and found that the agent actually learned human-like behaviors, such as following teammates and camping at the opponent’s base. Three examples of the automatic discovery behavior shown by the trained agent. These behaviors appear in the training process. Through reinforcement learning and group-level evolution, some behaviors—such as following teammates—are reduced as the agent learns to cooperate in a more complementary manner. The upper left shows the Elo ratings of 30 agents during training and development. The upper right corner shows the genetic tree of these evolutionary events. The chart below shows the development of knowledge, some internal rewards, and behavioral probability during the entire agent training process. Summary and outlook Recently, the research community has done very impressive work in the field of complex games, such as StarCraft 2 and Dota 2. Our paper focuses on the capture the flag mode of "Quaker III Arena", and its research contributions are universal. We would love to see other researchers rebuild our technology in different complex environments. In the future, we also hope to further improve the current reinforcement learning and group training methods. In general, we believe that this work emphasizes the potential of multi-agent training to promote the development of artificial intelligence: use the natural setting of multi-agent training and promote the development of powerful agents that can even cooperate with humans. KENNEDE ELECTRONICS MFG CO.,LTD. , https://www.axavape.com
From a multi-agent perspective, CTF requires team members to successfully cooperate with teammates and compete with opponents, while maintaining robustness in any game styles they may encounter.