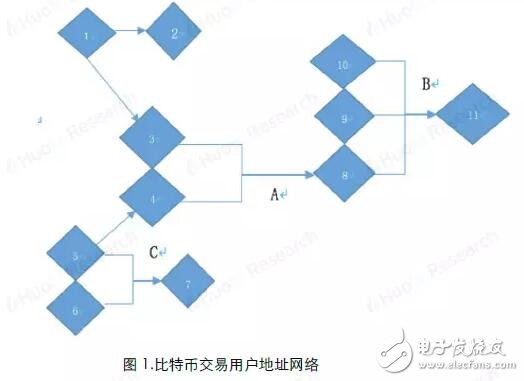
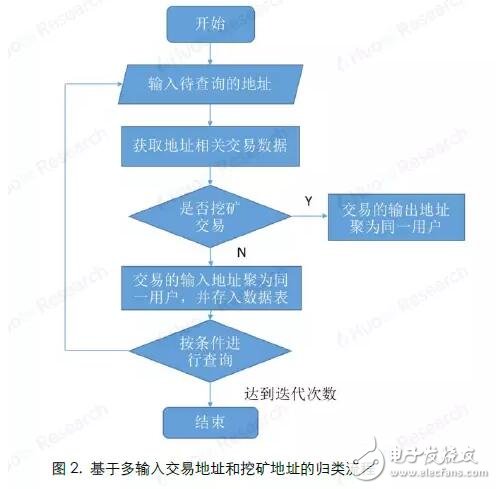
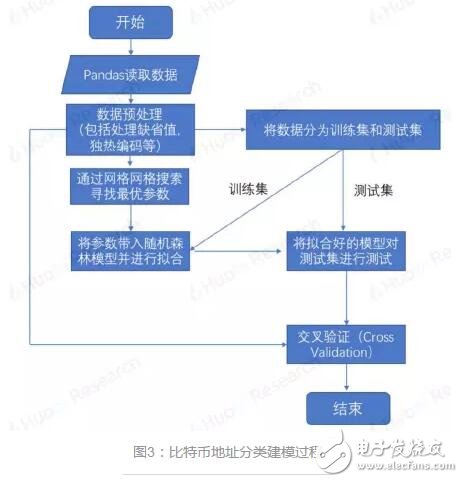
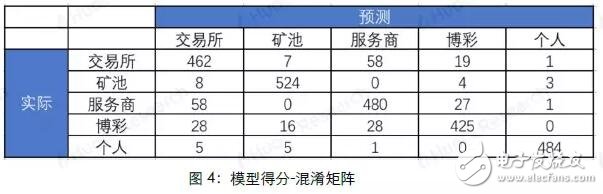
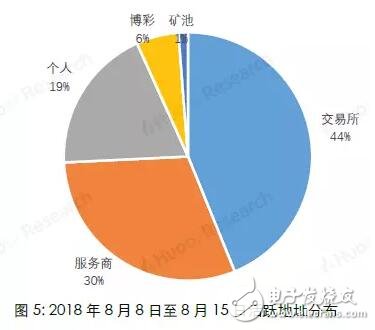
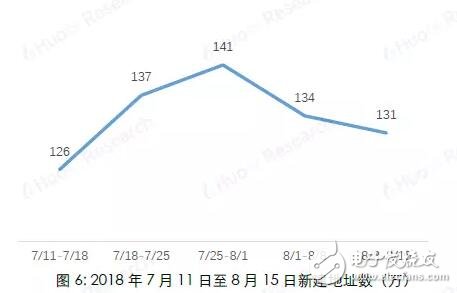
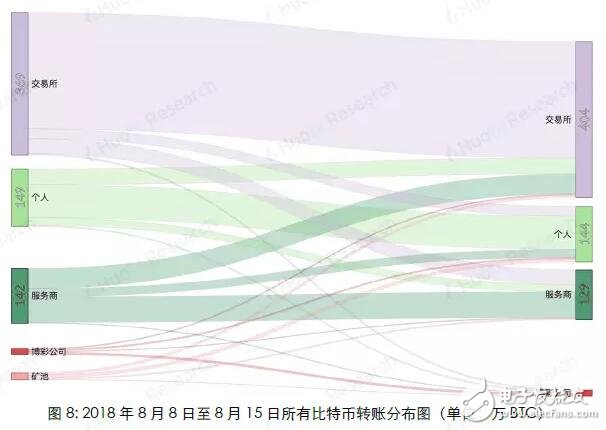
Because Bitcoin uses a public key-based wallet address as the user's identity on the blockchain network, and the wallet address is freely generated by the user and has nothing to do with the user's identity characteristics, the anonymity of Bitcoin makes it difficult for people to guess the user's true identity information. So far, there have been many attempts to speculate on the identity of Bitcoin addresses. The most commonly used speculation method is based on multi-input transaction addresses and mining transaction addresses. The accuracy of the judgment through recursive algorithms can reach almost 100%, which is very An effective way to track down the owner of a Bitcoin address. However, with the popularity of Bitcoin worldwide, the entire block of Bitcoin is now very large (as of August 28, 2018, the block height is 538862, and the size is close to 180G). If you use the recursion that this method relies on The algorithm calculates the addresses on the entire blockchain, which consumes a lot of computing resources and time, which limits the scope of use of this method; in addition, this method can only track part of the Bitcoin address owners who meet the conditions by setting certain conditions. It cannot cover all Bitcoin addresses. Based on the research results of this algorithm, Huobi Research Institute analyzes on-chain transfer information of different accounts by extracting features from the Bitcoin blockchain, and uses Random Forest's machine learning algorithm to classify address categories. The machine learning algorithm is not a replacement for the original clustering algorithm, but a supplement to the original clustering method application range. At the expense of a small amount of accuracy, it is applicable to the broader Bitcoin blockchain transfer research. This article is mainly divided into two parts: Part 1 1) Briefly describe the Bitcoin transaction system and transaction process 2) Classification method based on multi-input transaction addresses and mining transaction addresses 3) Classify address categories through random forest algorithm modeling Method 4) Comparison of the two algorithms. The second part uses the model to make an example analysis. The purpose is to provide readers with ideas for categorizing Bitcoin address owners, so that in different application scenarios, they can choose a more efficient method for multi-dimensional analysis of Bitcoin blockchain data. In the second part of the article, we analyzed all the Bitcoin addresses and transfer records from August 8 to August 15, 2018, and obtained the distribution of the number of active addresses based on the classification algorithm: Among the active addresses, 44% are exchange addresses, 30% are service provider addresses, 19% are personal wallet addresses, 6% are gaming companies, and 1% are mining pools. Further analysis of the number of newly created addresses and transfer details show that: 1) The number of new addresses added by exchanges and service providers has not changed much in the past few weeks, but the number of new personal wallet addresses has shown a significant downward trend. 2) The amount of Bitcoin transferred from personal addresses to exchanges is much greater than the amount transferred from exchanges to personal addresses. Finally, it is speculated that the reasons for the sharp drop in Bitcoin prices this week may include: 1) Decrease in the number of new investors entering the market. 2) It is very likely that a large number of users transfer bitcoins in their personal wallets to exchanges for selling. The first part of the model introduction Bitcoin transactions have three characteristics: 1) All transaction records are visible to the public, 2) A transaction can have multiple inputs (inputs) and multiple outputs (outputs) 3) Each transaction is identified by a public key-private key pair The payer and payee of the transaction. Figure 1 shows the transaction flow that actually appears on the Bitcoin network. Each vertex represents a Bitcoin address, and the line and arrow between the vertices represent a transaction. As the second feature of Bitcoin mentioned above, a transaction can have multiple inputs (transactions A, B, C in the figure), and the classification method based on multiple input transaction addresses and mining transaction addresses is used This feature. 2.1 Multiple input transaction addresses Through the research of Fergal Reid, MAO HL, MAN H, etc., it is concluded that when the user's payment amount exceeds the number of bitcoins in each available address in the user's wallet, in order to avoid performing multiple transactions to complete the payment, the transaction cost is The user will select multiple Bitcoin addresses from the wallet and aggregate them together for matching payment, realizing multi-input transactions. And because the funds in each address used in a bitcoin transaction require a separate signature, we can conversely think that all input addresses in a multi-input transaction originate from the same user. (The accuracy rate can be approximately 100%). Therefore, we can think that in Figure 1, 3 and 4 are the same user, the same is true: 8, 9, and 10, and 5 and 6 are all the same user. 2.2 Mining transaction address Similarly, for transactions without an input address (commonly known as mining transactions), since the essence of mining is to run a Bitcoin mining program on a server, it can be considered that the output address in a production transaction is owned by the same user Configure it. So if one or more addresses are the output of the same mining transaction, they can be considered to be controlled by the same user. In the case of the user's own mining mode, the accuracy of mining transaction address clustering can reach 100%. For the "mining pool" model, in most cases, the block reward will be transferred to the private income address of the "miner" in the output transaction, and then the secondary income distribution will be carried out according to the mining pool user's computing power contribution, so the output can also be considered The transaction output address belongs to the same user. 2.3 Classification process The framework of the classification algorithm is shown in Figure 2. The more the number of iterations, the more addresses will be found, and the better the comprehensiveness, but the increase in the number of iterations will also reduce the clustering efficiency. Above, we have described a classification model based on multiple input transaction addresses and mining addresses and its implementation method. This model can very accurately cluster the addresses of the same user, and as the number of iterations increases, the same user is obtained The number of addresses is very considerable: for example, if we know some hot wallet addresses of a certain exchange, a large number of other hot wallet addresses of this exchange can be obtained through this algorithm, and the accuracy rate is approximately 100%. However, the disadvantage of this algorithm is that it has certain limitations: we cannot know the owner of all addresses in the Bitcoin network, and we cannot classify an address that is not in the data table. Based on the research of the algorithm, Huobi Research Institute extracts the characteristics of different types of Bitcoin addresses from the Bitcoin blockchain and establishes an address classification model, which can classify a wider range of anonymous Bitcoin addresses. 3.1 Mark category and sample selection We randomly selected 8045 samples for modeling and divided them into five categories: exchange (1591), mining pool (1684), service provider (1669), betting company (1601), and individual (1500). The address label information used for modeling mainly comes from WalletExplorer(). The website has classified tens of thousands of addresses through the above methods, and has five different categories (exchanges, mining pools, service providers, betting companies, old addresses) , The old address category now has very few transaction records, we delete this category. In order to keep the number of data for each label at the same level for the remaining four categories, so as to avoid data imbalance, we adopted a random sampling method to keep the number of samples in each category at about 1500. In addition to the above four categories, we also added the category of "personal" Bitcoin addresses. The data comes from personal addresses that have been marked on blockchain.info, and 1,500 are randomly selected. 3.2 Feature selection Through empirical judgment and repeated observations and experiments, we selected the following address features as the modeling features: 1) The number of transactions that the address is used as input (total number of transfers) 2) The number of transactions with this address as output (total number of transfers) 3) The total amount of BTC inputted by this address (total BTC transferred out) 4) The total amount of BTC output from this address (total transfer in BTC) 5) When it is used as Input, the average total number of Inputs for each transaction 6) When it is used as Output, the average number of total inputs for each transaction 7) The ratio of the number of transfers in/out 8) (Number of transfers in-Number of transfers)/(Number of transfers + Number of transfers) 9) The average number of BTC transferred in each transaction 10) The average number of BTC transferred out per transaction 11) Have there been one or more mining transactions (Coinbase) 12) The address is used as the total miner fee of Input (total transaction fee for transfer out) 13) The address is used as the total miner fee of Output (total transaction fee for transfer in) 14) Average transaction fee for transfer out 15) Average transfer fee per transaction 16) Average number of transfers per day 17) Average number of transfers per day The data on the above chain Huobi Research Institute uses the BlockSCI tool to build a BTC node on the server, and then use Jupyter notebook to grab it. 3.3 Model selection In the selection of supervised learning models, through comparison and testing, we finally chose Random Forest as the model we built this time. The model mainly has the following four advantages: 1) In all current algorithms, it has excellent accuracy. 2) Ability to process input samples with high-dimensional features without dimensionality reduction. (Our data has a total of 17 dimensions of features) 3) Suitable for multi-classification problems (5 different classifications). 4) Good results can also be obtained for the default value problem (some addresses have only transfer-in but no transfer-out records, and data related to transfer-out cannot be calculated). 3.4 Modeling process The modeling process is shown in Figure 3. The main parameters of grid search are: 1) The number of trees in the random forest (n_estimators) 2) Maximum depth of the tree (Max_depth) 3) The minimum number of samples required to split internal nodes (Min_samples_split) 4) The minimum number of samples required by leaf nodes (Min_samples_leaf) The solution is implemented in Python3 language, using RandomForestClassifier (random forest classification), GridSearchCV (grid search), train_test_split (separation of test set and training set), confusion_matrix (confusion matrix), K-Fold (K-fold ) And other API modules. The training set and the test set are divided according to the ratio of 2:1. 3.5 Model score After debugging, the model has an accuracy of 90% on the final test set. The confusion matrix is ​​shown in Figure 4. Excluding the forecast confusion of exchanges and service providers, the overall effect is relatively satisfactory. The Bitcoin classification algorithm (Algorithm 2) of Huobi Research Institute does not replace the multi-input transaction address and mining address classification algorithm (Algorithm 1), but uses the results of Algorithm 1 as the address label, and applies it on the basis of Algorithm 1. The scope is supplemented. By sacrificing a small part of accuracy, it can improve its universality to be applied to more macro-chain data analysis. The main differences between the two are: 4.1 Different types of algorithms Algorithm 1 is the process of searching for addresses that appear in the same transfer at the same time through multiple iterations when the tag address is known. The purpose is to find the address that belongs to the same user as the known tag address. It is essentially a recursive algorithm. , The more iterations, the more marked addresses will be obtained. Algorithm 2 is a supervised learning algorithm in machine learning. First, a large amount of labeled data is trained to generate a classifier with inference function. With this classifier, any new individual can be classified according to its characteristics. 4.2 Different label sources Algorithm 1 and Algorithm 2 both extract data from the Bitcoin blockchain, but the source of the tags is different: The label source of Algorithm 1 can be observed in practice. For example, if you want to obtain the hot wallet address of a certain exchange, you can actually perform deposit and withdrawal transactions on the exchange. The exchange deposit and withdrawal addresses are the wallet addresses of the exchange; and Algorithm 2 requires a huge number of tags ( At least several thousand addresses), so the results of Algorithm 1 are directly quoted. For example, some websites such as WalletExplorer can directly provide the required tags. 4.3 Different application scenarios Algorithm 1 advantage: 1) The accuracy rate is very high (close to 100%) 2) There are specific labels (specific to Huobi Hot Wallet, OKEX Hot Wallet, etc.) 3) Strong interpretability Disadvantages: 1) Poor universality (cannot label all addresses) 2) Recursive algorithm consumes a lot of computing resources This algorithm is suitable for tracking the Bitcoin flow of a certain person (hacker, Bitcoin thieves) or a certain group (exchanges, service providers). Algorithm 2 advantage: 1) Strong universality (given any address and its characteristics on the chain, the type of the address can be inferred) 2) In addition to the consumption of certain computing resources for modeling, a very small amount of computing resources are consumed when categorizing. Disadvantages: 1) The accuracy rate cannot be compared with Algorithm 1 (currently it can only reach 90%). 2) No specific label (can only be classified into five categories, not specific to a certain exchange or institution). 3) The label may change with the behavior (maybe an address is initially labeled as a personal address, but it may be changed to an exchange address in the future) 4) Poor interpretability (random forest is a black box). This algorithm is suitable for macro-chain data analysis that requires slightly lower data accuracy (for example, what percentage of all bitcoins are currently on exchanges, and what percentage are in personal wallets, etc.), and according to an address, Quickly determine the address category (for example, a large transfer occurred on the Bitcoin chain on a certain day to enter an address, and the classification algorithm can be used to infer what category the address belongs to) In actual analysis, our solution to the problem of how to improve the accuracy of Algorithm 2 is: Combine Algorithm 2 with Algorithm 1, and use Algorithm 1 to classify as many addresses as possible when the computing power conditions are sufficient. (Especially for addresses with a large number of currency holdings or a large number of transfers, it is impossible to cluster and search for tags online). Use Algorithm 2 to classify the remaining addresses that cannot be classified. Can effectively improve data accuracy. We select all Bitcoin addresses and transfer records from August 8 to August 15, 2018 for analysis. First, algorithm 1 is used to cluster all the addresses that appeared in input and output in this week, and then algorithm 2 is used to classify the remaining addresses. The number of active addresses in the week was 3.32 million. According to the calculation, 1.43 million were exchange addresses, 990,000 were service provider addresses, 620,000 were personal addresses, 180,000 gaming companies, and 40,000 mining pools. The distribution is shown in Figure 5. Among them, exchanges, service providers and personal wallet addresses accounted for 93% of the total addresses. We have taken four weeks of on-chain data for analysis: Judging from the number of new addresses (Figure 6), the number of new addresses has decreased in the past few weeks; We then classify the number of new addresses using our algorithm (Figure 7), and we can find that although the number of new addresses added by exchanges and service providers has not changed much in the past few weeks, the number of new personal wallet addresses has decreased significantly. The trend has directly led to a decrease in the overall number of newly created addresses. It can be judged by the decrease in the number of newly-built personal wallet addresses, and the number of new investors entering the market has decreased. In addition, in addition to address analysis, we analyzed the transaction data for the week. The result is shown in Figure 8. There was a total of 6.91 million BTC in this week. The amount of bitcoins in personal addresses transferred to the exchange is much larger than the amount transferred from the exchange to the personal address (a difference of 140,000 BTC, about 840 million U.S. dollars), which is very large The probability is that a large number of users transfer the bitcoins in their personal wallets to exchanges for selling, which may also be one of the reasons for the drop in bitcoin prices that week. From August 8th to August 15th, 2018, the digital currency was generally in a downturn, and the price of Bitcoin dropped by 15%. Through the above analysis, the sharp drop in Bitcoin prices this week may be related to two factors: 1) The decrease in the number of new addresses created by individuals indicates a decrease in the number of new investors entering the market. 2) The amount of bitcoins in personal addresses transferred to exchanges is far greater than the amount transferred from exchanges to personal addresses. There is a high probability that a large number of users transfer bitcoins in personal wallets to exchanges for dumping. The KSPOWER brand H series - 5 in 1 dimmable led driver provides 0-10V 1-10V triac/phase resistance pwm dimmable constant voltage single output LED Drivers with 5 years warranty. The low voltage lighting transformer can make the output wattage of MAX 320W and accept 12Volt, 24Volt, 36Volt and 48Volt output voltage optional. The led downlight driver is Class 2 Class P rated, and both UL/cUL, FCC CE ENEC GS Listed and SELV style enclosures. The PWM LED driver is flicker free design and protections for short circuit, over load, over voltage and over temperature. The outdoor lighting transformers use low profile aluminum metal housing with IP65 IP67 rating environment protection for indoor or outdoor use, with junction box makes 0-10V 1-10V phase pwm dimming led driver the power solutions for LED strips, LED signs, billboard and landscape lighting. The led dimmable driver featuring built-in PFC function more than 0.95 and outstanding led dimming performance. low voltage lighting transformer, outdoor lighting transformers, transformer driver, led dimmable driver, led downlight driver Shenzhenshi Zhenhuan Electronic Co., Ltd , https://www.szzhpower.com