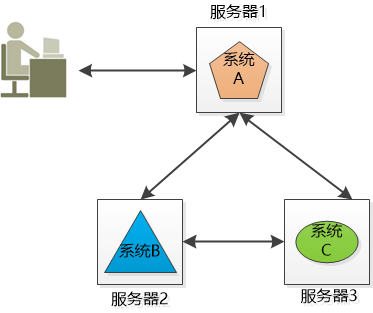
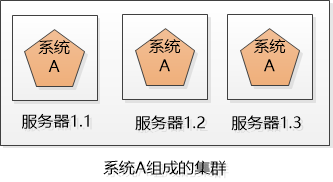
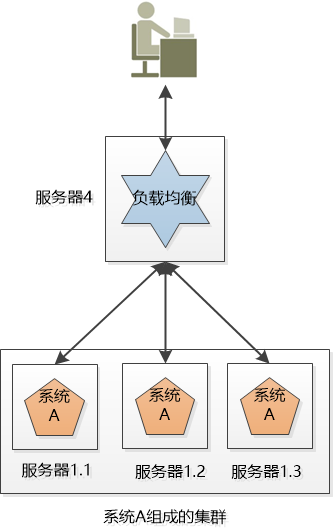
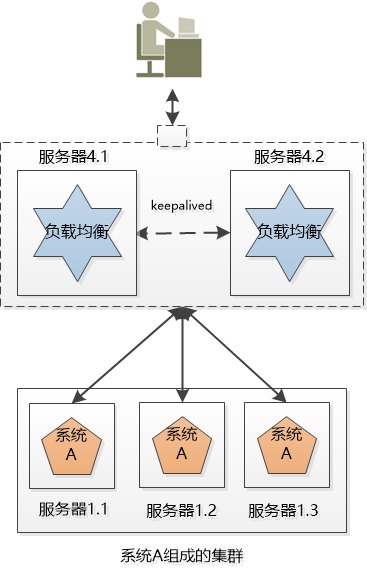
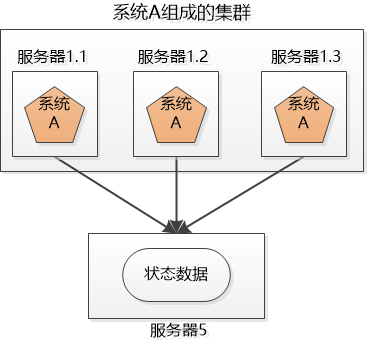
1. Distributed Xiao Ming’s company has 3 systems: System A, System B, and System C. These three systems do different business. They are deployed on 3 independent machines and call each other (of course, cross-domain networks). ), work together to complete the company's business processes. Distribute different businesses in different places, which constitutes a distributed system. Now the problem is coming. System A is the "face" of the entire distributed system. It is directly accessed by users. When the number of users is large, it is either speed It’s so slow, or just hang up, what should I do? Since there is only one copy of system A, it will cause a single point of failure. 2 cluster (Cluster) Xiao Ming’s company is not bad, so buy a few more machines. Xiao Ming deploys several copies of System A (for example, the three servers in the figure below), each of which is an instance of System A, and provides the same externally. Service, so I can sleep peacefully, I am not afraid that one of them is broken, I have the other two. The systems on these 3 servers form a cluster. But for the user, system A suddenly appeared, and the IP address of each system was different. Which one did they visit? If everyone accesses server 1.1, then server 1.1 will be exhausted, and the remaining three will become a waste of money. 3 Load Balancer Xiao Ming needs to balance the work of System A on the three machines as much as possible. For example, if there are 30,000 requests, let the three servers handle 10,000 each (of course, this is an ideal situation). This is called load balancing. Obviously, this load balancing work is best done independently and placed on a separate server (such as Ngnix): Later, Xiao Ming discovered that although the work content of this load-balanced server is very simple, that is, it receives requests and distributes requests, but it may still hang, and single points of failure may still occur. There is no way, but the load balancing is also made into a cluster, but there are two differences from the cluster of system A: 1. Although there are two machines in this new cluster, we can use some way to make this cluster only provide one IP address to the outside, which means that the user sees only one machine. 2. At the same time, we only let one load-balanced machine work, and the other is on standby. If the one who is working hangs up, the one who is on standby will go up. 4 flexibility If these 3 instances of system A still cannot satisfy a large number of requests, add another server! Double 11 came, and the number of users was 10 times that of usual. Xiao Ming applied to the leader for a fee and bought dozens of servers and deployed dozens of copies of System A at once. However, after Double 11, the traffic dropped suddenly, and those dozens of servers were no longer used and turned into decorations! After being criticized by the leader, Xiao Ming decided to try cloud computing. You can easily create and delete virtual servers in the cloud, so that you can easily increase or decrease servers dynamically according to user requests. When Double 11 comes, create a virtual server, and when Double 11 is over, turn off the unused ones to save money. So Xiao Ming's system has a certain degree of flexibility. 5 failover The above system looks good, but it makes an unrealistic assumption: All services are stateless. In other words, it is assumed that the two requests of the user are directly unrelated. But the reality is that most services are stateful, such as shopping carts. The user accesses the system, creates a shopping cart on the server 1.1, and adds several products to it, and then the server 1.1 hangs, and the user cannot find the server 1.1 for subsequent visits. At this time, failover is required. Let other servers take over and process user requests. But the question is, is there a user's shopping cart on the server 1.2, 1.3? If not, users will complain, where is the shopping cart I just created? More serious, suppose the user logs in on the server 1.1, and the user logged in information is saved in the server's session. Now that the server is down, the user's session is naturally gone. When the user is invalidated and transferred to When on other servers, the other servers found that the user was not logged in, and kicked the user to the login interface and asked the user to log in again! Status, status, status! The user's login information, shopping cart, etc. are all status information. If the status is not handled well, the power of the cluster will be greatly reduced, and true failover cannot be completed, or even use. How to do? One way is to replicate the state information among the servers in the cluster so that the servers in the cluster can reach an agreement. Who will do this? It can only be an application server like Websphere, Weblogic. Another way is to store the state information in one place so that all servers in the cluster can access: Xiao Ming heard that Redis is good, so use Redis to save it! Sata Cable With Latch,Sata Cable With Led,Sata Cable With Power,Mini Sas 36P Connector Dongguan Aiqun Industrial Co.,Ltd , https://www.gdoikwan.com