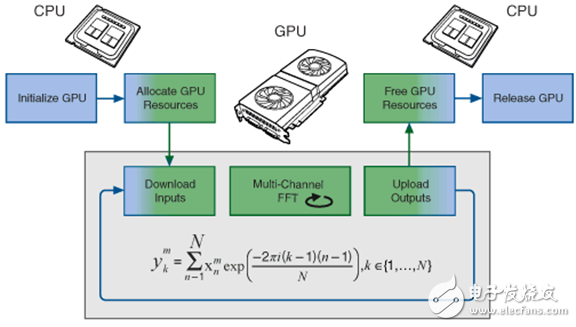
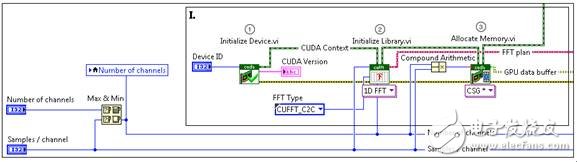
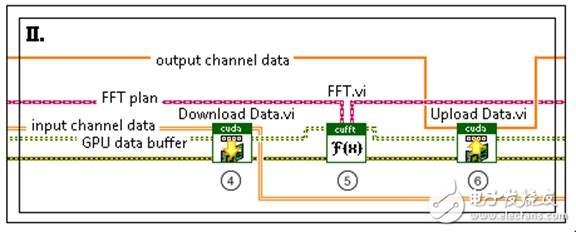
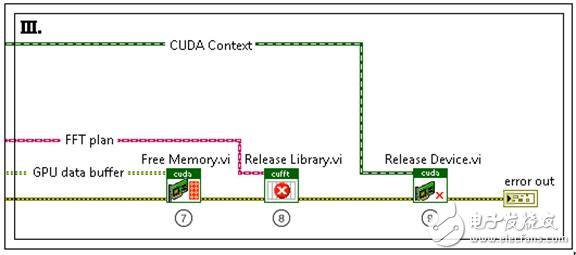
Platforms with parallel processing architectures, such as FPGAs and GPUs, are widely used to quickly analyze large data sets. These two techniques can alleviate the CPU burden of computationally intensive algorithms and process them on highly parallel platforms. FPGAs have high flexibility and low processing latency, but they have some limitations in floating-point operations due to insufficient capacity. GPUs have become a popular choice for parallel processing because of their flexibility, convenience, and low cost. They can successfully work with FPGAs to optimize the execution speed of an algorithm. For example, in an algorithm, when the GPU analyzes floating point data, inline calculations can be performed quickly on the FPGA. NVIDIA® Compute Unified Device Architecture (CUDATM), which helps create GPU-based algorithms, allows CUDATM to create code using the C programming language and its NVIDIA extensions. Figure 1. FPGA and GPU can work with the CPU to optimize performance. For many applications in the real-time high-performance computing world, data and task requirements can be mapped to the GPU for processing. The algorithmic application of high-intensity arithmetic operations is very suitable for processing on the GPU; if the ratio of arithmetic operations to memory operations in an application is high, it indicates that when the computation task is solved on the GPU architecture, significant speed improvement can be achieved. For example, for applications that handle multi-channel operations (such as the ability to compute several FFT transforms in parallel), or mathematical operations (such as large matrix operations), they can be effectively mapped to the GPU. The LabVIEW GPU Analysis Toolkit enables developers to take full advantage of the GPU parallel architecture in the LabVIEW application framework. The toolkit leverages the capabilities of NVIDIA's CUDA toolkit, as well as the CUBLAS and CUFFT libraries, while allowing developers to directly call those GPU code already written in the LVGPU SDK. The LabVIEW GPU Analysis Toolkit allows developers to leverage the core resources of NVIDIA CUDA and CUBLAS and CUFFT methods, which can be called in LabVIEW. For advanced operations, using the code already developed in CUDA, you can use the LabVIEW GPU Analysis Toolkit to transfer computational tasks to the GPU. Note that the toolkit will not be able to compile LabVIEW code for the GPU, but it can use packaged CUDA functions or custom CUDA kernel code in LabVIEW. In a unique device execution environment (ie CUDA environment), advanced custom kernel code can be safely called during LabVIEW execution by processing CUDA core program operations and their parameters. The environment also ensures that all GPU resources and functional requirements are properly managed. The advent of the LabVIEW GPU Analysis Toolkit enables scientists and engineers to perform large-scale data acquisition, transfer blocks of data to the GPU for fast processing, and view processed data in a unified LabVIEW application. Common signal processing techniques and mathematical operations, such as fast Fourier transform of the signal, can be achieved by directly calling the corresponding VI in the NVIDIA library. This way, developers can quickly prototype an application using all available computing resources. For those complex applications already in CUDA, they can be used in LabVIEW to process data quickly using custom algorithms. In general, using the LabVIEW GPU Analysis Toolkit to communicate with the GPU can be broken down into three phases: GPU initialization, performing operations on the GPU, and releasing GPU resources. The following sections discuss the use of the LabVIEW GPU Analysis Toolkit to transfer an FFT computation task from the CPU FFT to the GPU. Figure 2. Program flow for transferring an FFT operation task from the CPU to the GPU for analysis. This example performs FFT operations on simulated signals from multiple simulation channels to simulate the acquisition of multi-channel input data from DAQ devices or log files. This workflow is a typical process of transferring an FFT operation task from the CPU to the GPU for analysis. Figure 3. Initializing GPU resources First, it is necessary to choose a GPU device. Next, a CUDA environment will be created to enable communication between LabVIEW and the GPU. This is done by using the IniTIalize Device VI. Next, the GPU will prepare for the FFT operation by selecting the type of FFT. This type includes information such as the FFT size, the number of FTTs performed in parallel on the GPU, and the data type of the input signal or spectral line. This process will reserve resources on the GPU for maximum performance. The Allocate Memory VI creates a memory buffer on the GPU for data transfer between the CPU and the GPU for FFT operations. It stores the channel data for download to the GPU and the data results that are ready to be uploaded to the CPU after the GPU has completed the calculation. Figure 4. Performing FFT communication on the GPU First, the calculation is performed by transferring data from the CPU to the buffer of the GPU. When performing FFT calculations on the GPU, its large-scale parallel architecture is used to simultaneously compute the FFT for each channel. When the calculation is complete, the data is transferred from the GPU's buffer back to the array in the CPU. The Download Data VI transfers the multi-channel data stored in the LabVIEW array from the CPU to the buffer that was allocated during the initialization phase. The FFT VI calculates its spectrum in parallel for each downloaded channel data. Finally, the Upload Data VI transfers the spectral data stored in the GPU buffer back to the LabVIEW array for further processing by the CPU. Figure 5. Freeing GPU resources The last step is to release the GPU resources initialized in the first step. The Free Memory VI releases the buffer on the GPU that is used to store FFT data. The Release Library VI releases the resources left on the GPU during the initialization of the FFT operation. Finally, the Release Device VI releases the GPU resources reserved for GPU communication during the CUDA environment initialization process. Using LabVIEW GPU analysis tools, developers can transfer important operations to the GPU for processing, freeing up CPU resources for other tasks. This provides LabVIEW users with a very powerful and unprecedented processing resource. Now, whether using FPGAs and CPUs or GPUs, the acquired data can be processed quickly and viewed from a single LabVIEW application. As a result, users can more effectively utilize system resources while minimizing the computational cost of highly parallel data processing operations and conversions. Diy Breadboard Kit,Breadboard And Jumper Wire Kit,Large Breadboard Kit,Breadboard Prototyping Kit Cixi Zhongyi Electronics Factory , https://www.cx-zhongyi.com