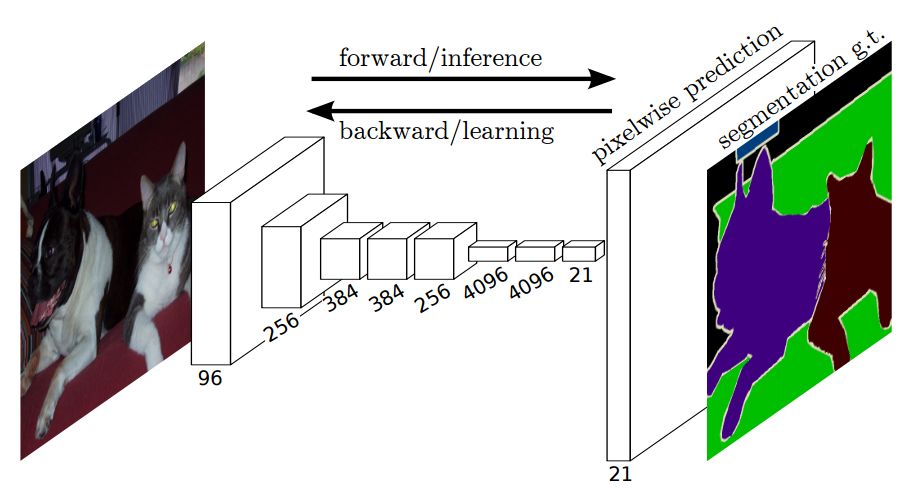
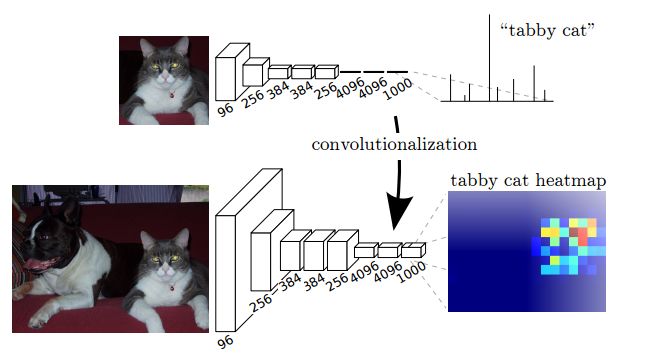
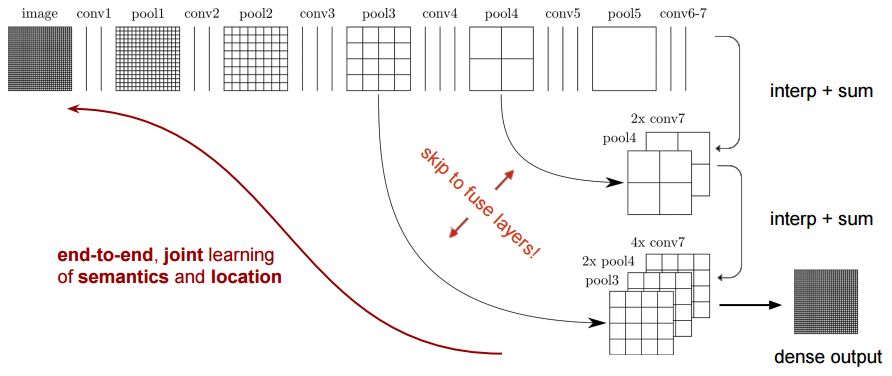
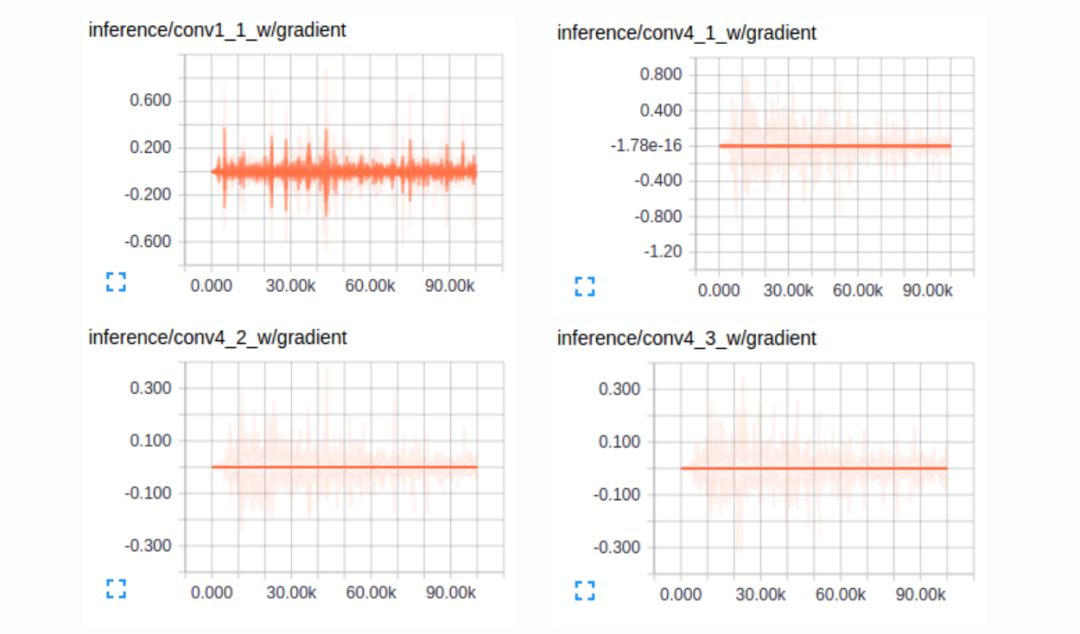
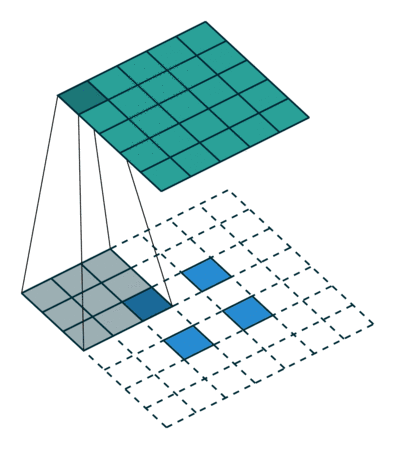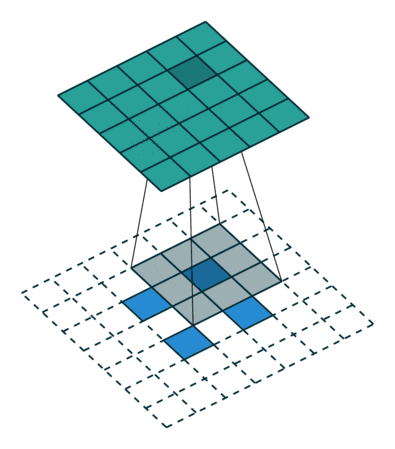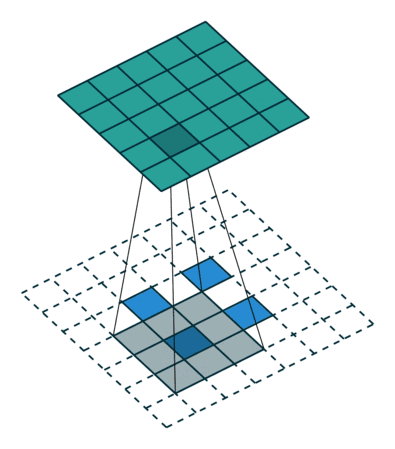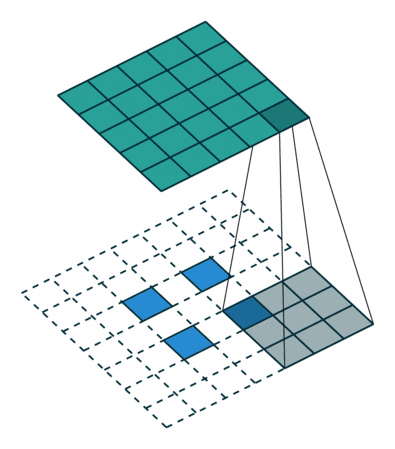
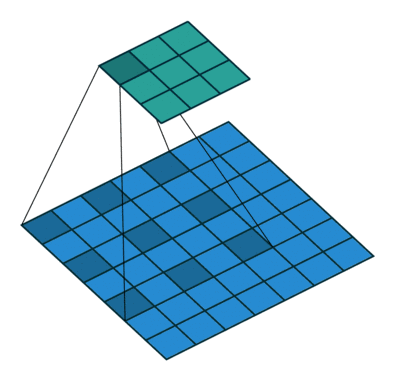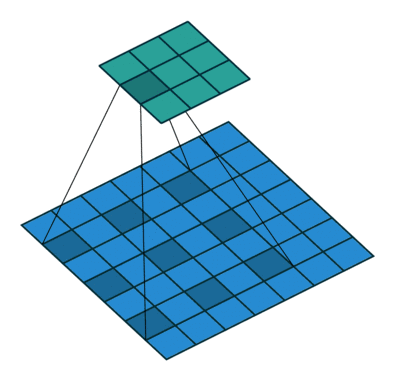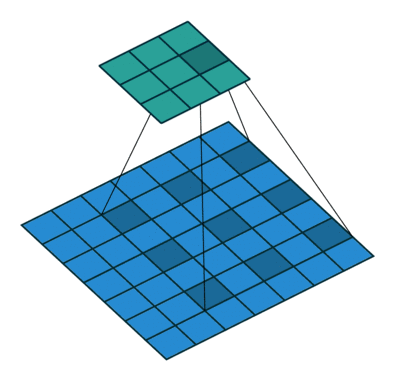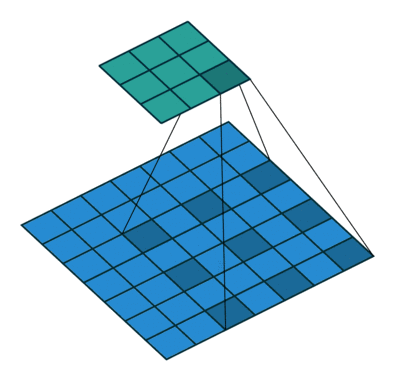
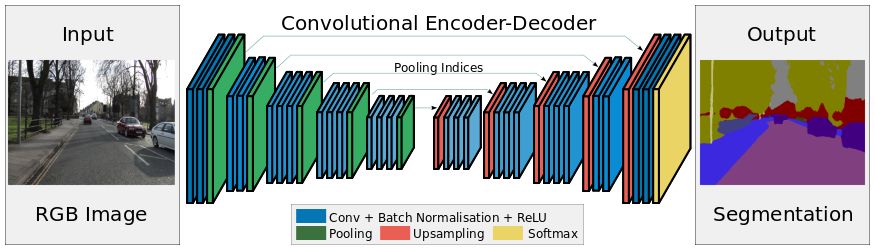
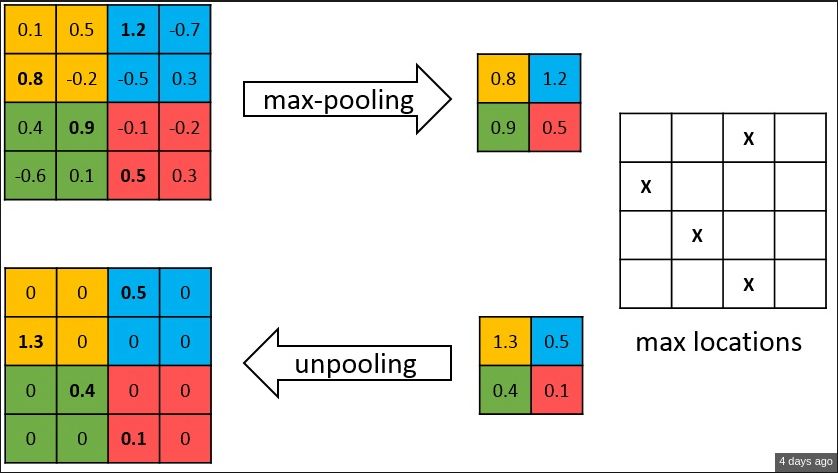
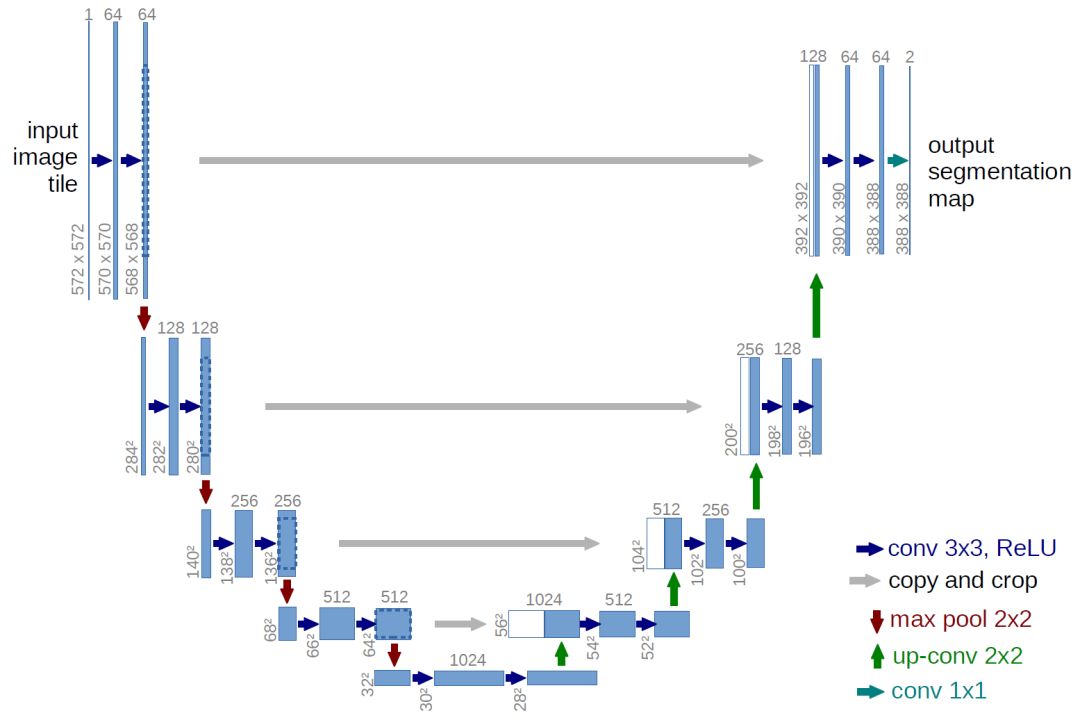
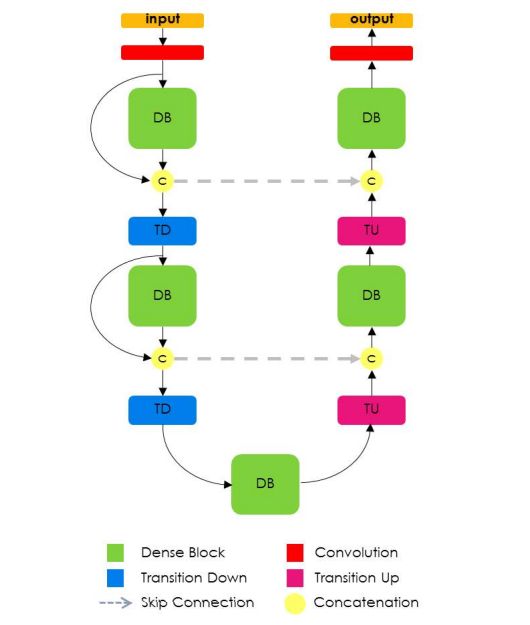
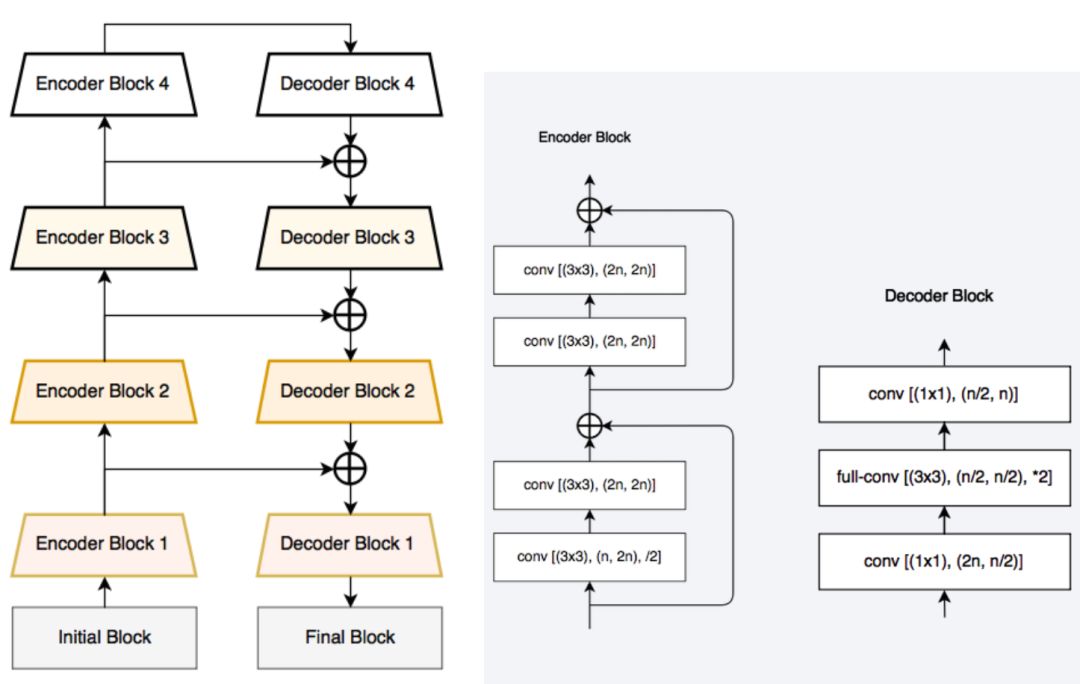
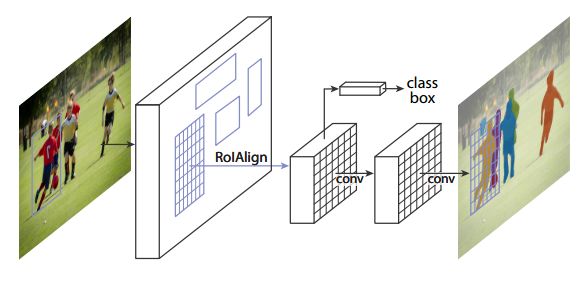
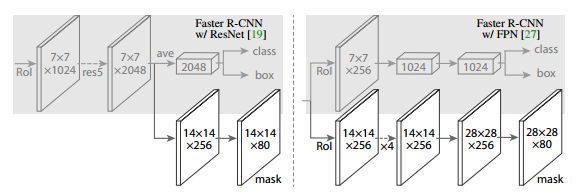
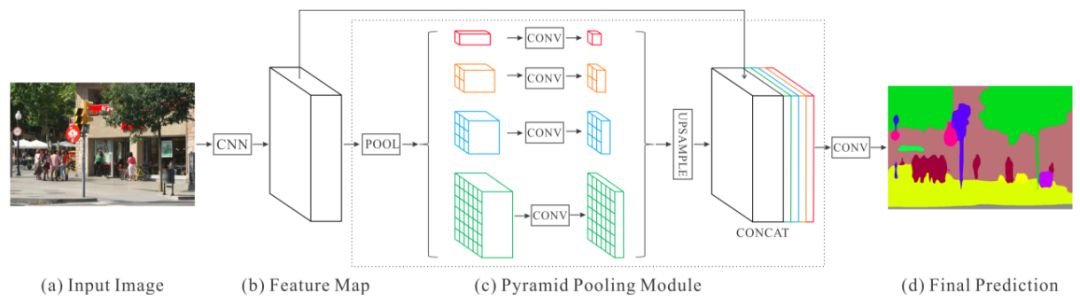
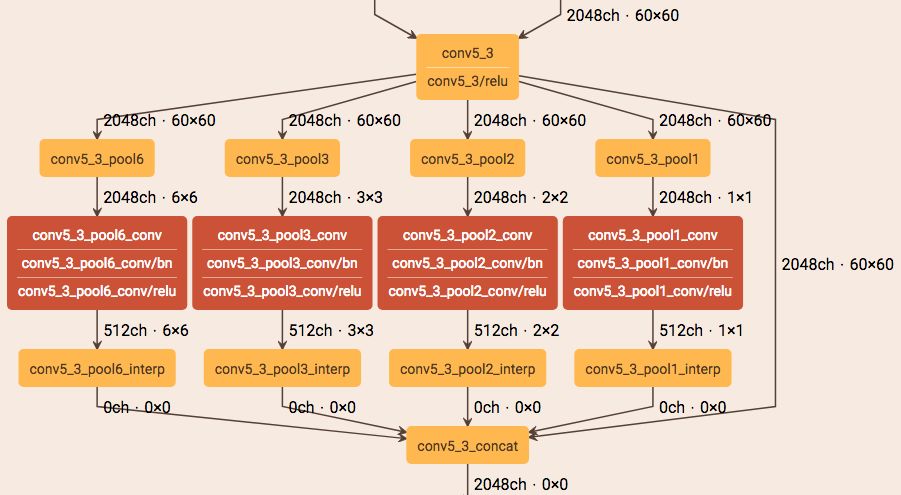
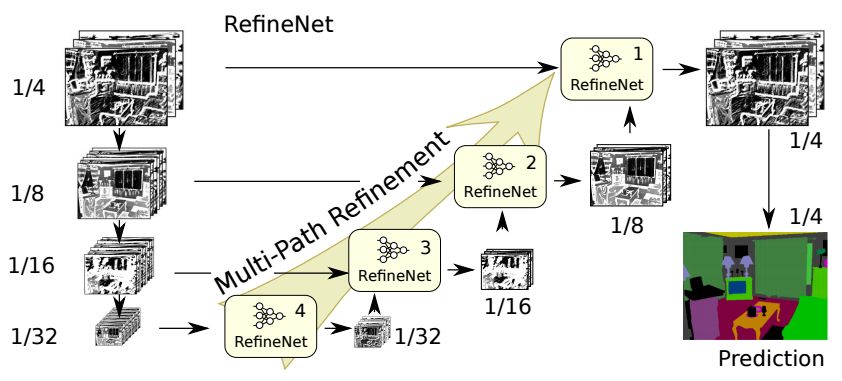
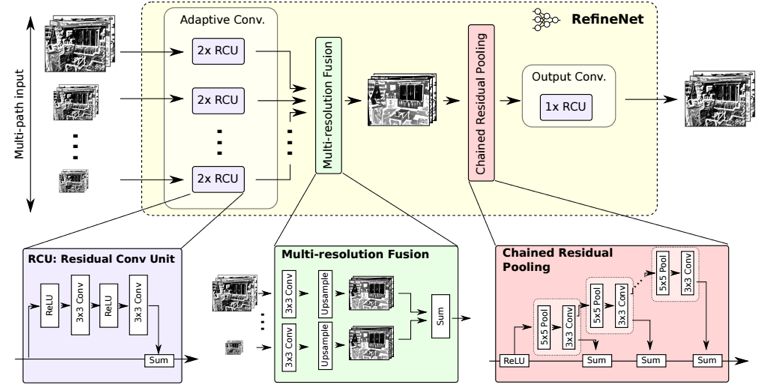
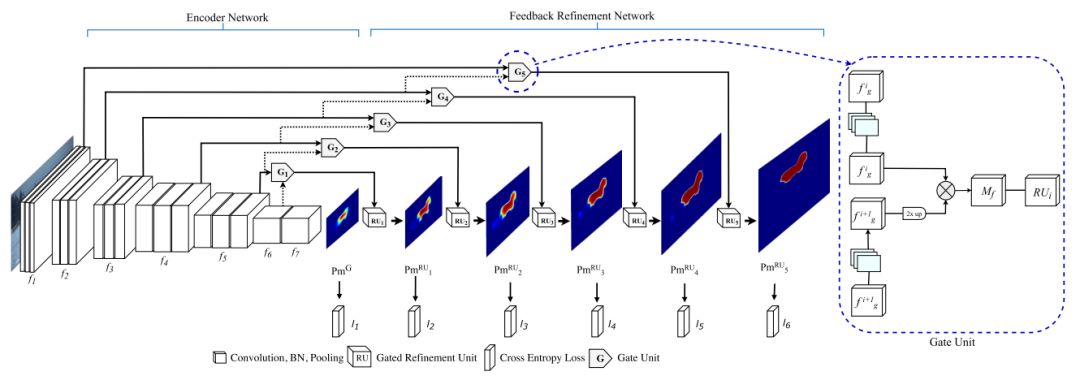
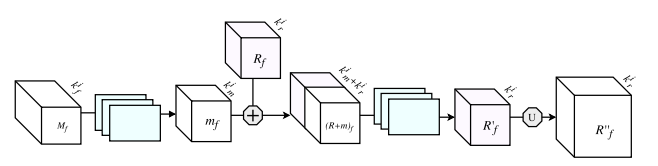
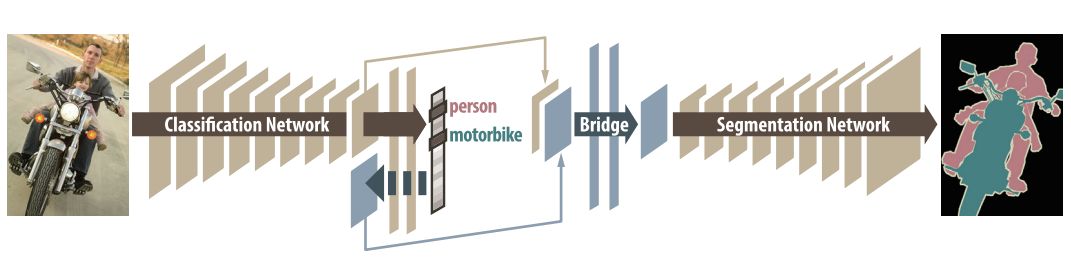
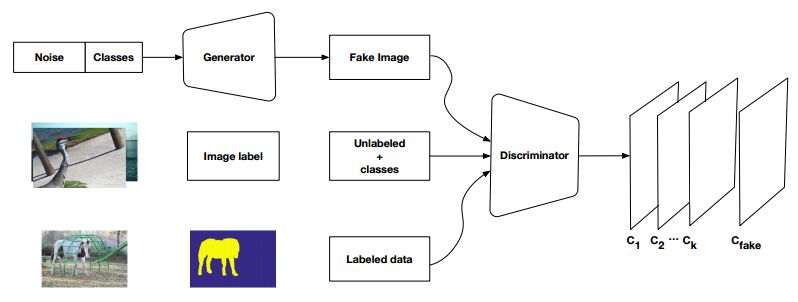
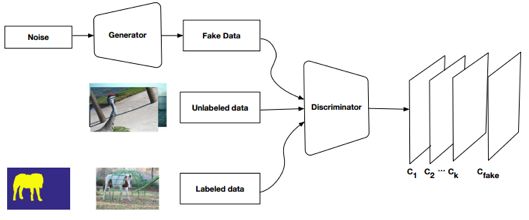
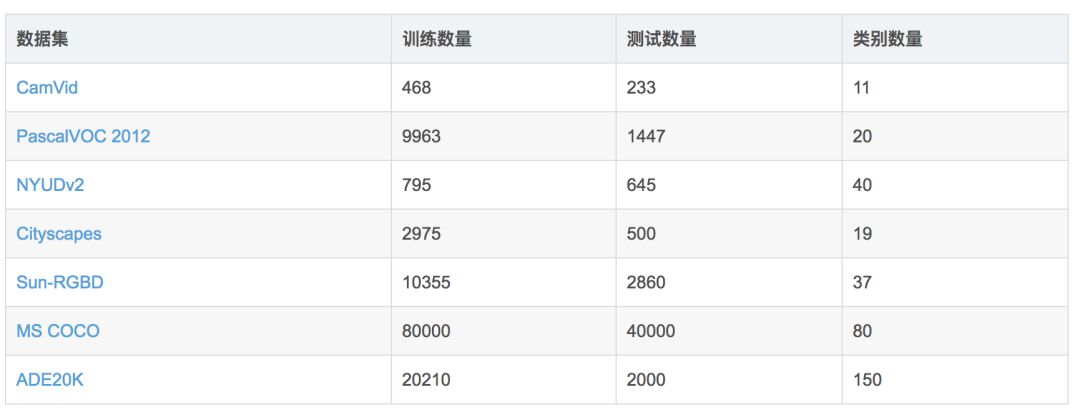
The semantic segmentation of the image is to assign a semantic category to each pixel in the input image to obtain pixelated dense classification. Although semantic segmentation/scene resolution has been a part of the computer vision community since 2007, it is similar to other areas in computer vision. Long et al. (2014) first used full convolutional neural networks to perform end-to-end natural imagery. Segmentation and semantic segmentation have made major breakthroughs. Figure 1: Input image (left), semantic segmentation diagram generated by FCN-8s network (right) (using pytorch-semseg training) The performance of the FCN-8s architecture on the Pascal VOC 2012 dataset is 20% better than the previous method, reaching 62.2% mIOU. This architecture is the basis of semantic segmentation, and hereafter some new and better architectures are based on this. Full convolutional networks (FCNs) can be used for semantic segmentation of natural images, multimodal medical image analysis, and multispectral satellite image segmentation. Similar to deep classification networks such as AlexNet, VGG, and ResNet, FCNs also have a large number of deep-seated frameworks for semantic segmentation. The authors summarize FCN, SegNet, U-Net, FC-Densenet E-Net and Link-Net, RefineNet, PSPNet, Mask-RCNN, and some semi-supervised methods, such as DecoupledNet and GAN-SS, and provide some of these networks PyTorch implementation. In the last part of the article, the author summarized some popular data sets and showed some of the results of network training. Network architecture The general semantic segmentation architecture can be thought of as an encoder-decoder network. The encoder is usually a pre-trained classification network like VGG, ResNet, and then a decoder network. The difference between these architectures lies mainly in the decoder network. The task of the decoder is to semantically map discriminative features (lower resolution) learned by the encoder to pixel space (higher resolution) to obtain dense classification. Different from the final result of the deep network in the classification task (ie, the probability of the existence of a class) is considered as the only important thing. Semantic segmentation requires not only the discrimination ability at the pixel level, but also the ability to learn the encoder at different stages. Distinguish feature mapping to pixel space. Different architectures use different mechanisms (long jump connections, pyramid pooling, etc.) as part of the decoding mechanism. Some of the above architecture and code for loading data are available at the following link: Pytorch: https://github.com/meetshah1995/pytorch-semseg This paper makes a more formal summary of semantic segmentation (including Recurrent Style Networks). Fully Convolution Networks (FCNs) Full Convolutional Network We have modified the current classification networks (AlexNet, VGG net and GoogLeNet) to full convolutional networks, and fine-tuned the segmentation tasks to transfer the learning characterization to the network. We then define a new architecture that combines deep, coarse network-level semantic information with shallow, fine-grained network-level surface information to generate accurate segmentation. Our full convolutional network is PASCAL VOC (relatively 20% prior to 2012, achieving an average IU of 62.2%). Optimal segmentation results are achieved on NYUDv2 and SIFT Flow. For a typical image, the inference It only takes one-third of a second. Figure 2: FCN end-to-end intensive forecasting process Key features: The features are merged from different stages in the encoder and they differ in the degree of roughness of the semantic information. Upsampling of the low resolution semantic feature map is accomplished using a deconvolution operation initialized by a bilinear interpolation filter. Semantic segmentation is achieved by using excellent samples of knowledge transfer from modern classifier networks such as VGG16 and Alexnet. Figure 3: Convert a fully connected layer into a convolutional layer so that the classification network can output a class heat map. As shown above, the fully connected layer (fc6, fc7) of the VGG16 classification network is converted to a full convolutional layer. It generates a heat map of a low-resolution class, then deconvolutes it with bilinear initialization, and merges (adds simply) the lower layers (conv4 and conv3) in VGG16 at each stage of the upsampling. The more coarse but higher resolution feature maps further refine the features. A more detailed netscope-style network visualization can be found here. In traditional classified CNNs, pooling operations are used to increase the field of view while reducing the resolution of feature maps. This is very useful for categorization tasks, because the ultimate goal of classification is to find the existence of a particular class, and the spatial location of the object does not matter. Therefore, a pooling operation is introduced after each convolution block so that subsequent blocks can extract more abstract, prominent class features from the pooled features. Figure 4: FCN-8s Network Architecture On the other hand, pooled and stepped convolutions are detrimental to semantic segmentation because these operations result in the loss of spatial information. Most of the architectures listed below mainly use different mechanisms in the decoder, but all aim at recovering the information lost when the resolution is reduced in the encoder. As shown in the above figure, FCN-8s incorporates features of different roughnesses (conv3, conv4, and fc7), and uses the spatial information at different resolutions of the encoder at different stages to refine the segmentation results. Figure 5: Convolutional layer gradients when training FCNs The first convolutional layer captures low-level geometry because it depends entirely on the dataset. You can notice that the gradient adjusts the weight of the first layer to adapt the model to the dataset. The deeper convolutional layers in VGG have a very small gradient flow because the high-level semantic concepts captured here are sufficient for segmentation. Figure 6: Deconvolution (convolution transposition) Hollow Convolution Another important aspect of the Semantic Separation Architecture is the use of deconvolution for feature maps, upsampling of low-resolution segmentation maps into the input image resolution mechanism, or costly computational costs, using hollow convolutions to avoid resolution on the part of the encoder The rate dropped. Even on modern GPUs, the computational cost of empty convolutions is high. Paper links: https://arxiv.org/abs/1411.4038 SegNet The novelty of SegNet lies in the way the decoder upsamples its lower resolution input feature map. Specifically, the decoder uses the pooling index calculated in the maximum pooling step of the corresponding encoder to perform nonlinear upsampling. This method eliminates the need for learning upsampling. The up-sampled feature map is sparse, so the convolution operation is then performed using a trainable convolution kernel to generate a dense feature map. The proposed architecture is compared with the widely used FCN and the well-known DeepLab-LargeFOV, DeconvNet architecture. The result of the comparison reveals the trade-off between memory and precision involved in achieving good segmentation performance. Figure 7: SegNet Architecture Key features: SegNet uses de-pooling in the decoder to upsample the feature map and maintain the integrity of the high-frequency details in the segmentation. The encoder does not use a fully connected layer (convolution like FCN) and is therefore a lightweight network with few parameters. Figure 8: Depooling As shown in the above figure, the index of each largest pooled layer in the encoder is stored for later use of those stored indexes in the decoder to depool the corresponding feature map. This helps maintain the integrity of high-frequency information, but when de-pooling low-resolution feature maps, it also ignores nearby information. Paper links: https://arxiv.org/abs/1511.00561 U-Net The U-Net architecture includes a narrow path to capture context information and a symmetrical extension path to support precise localization. We have demonstrated that such a network can use very few images for end-to-end training and achieve superior performance in the ISBI Neuron Structure Segmentation Challenge than the best method (a sliding window convolutional network). We used the same network to train on transmitted-light microscopy images (phase contrast and DIC) and obtained the 2015 ISBI Cell Tracking Challenge with great advantages. In addition, the network is inferred quickly. A 512x512 image segmentation took less than a second on the latest GPU. Figure 9: U-Net architecture Key features: U-Net simply splices the feature map of the encoder to the upsampled feature map of each stage decoder, thus forming a trapezoidal structure. This network is very similar to the Ladder Network type architecture. With the architecture of the long jump splicing connection, the decoder is allowed to learn the relevant characteristics lost in the encoder pooling at each stage. U-Net achieved the best results on the EM dataset, which has only 30 densely-labeled medical images and other medical image data sets. U-Net later expanded to the 3D version of 3D-U-Net. Although U-Net's publication was due to its segmentation in the biomedical field, its practicality in the network, and its ability to learn from very little data, it has now been successfully applied in several other fields, such as satellite image segmentation, and has also become a number of kaggles. Part of the solution to the victory of medical image segmentation in the competition. Paper links: https://arxiv.org/abs/1505.04597 ▌Fully Convolutional DenseNet In the article we have extended DenseNets to solve the problem of semantic segmentation. We achieved the best results on urban scene benchmark datasets such as CamVid and Gatech, without the use of further post-processing modules and pre-training models. In addition, because of the superior structure of the model, our method has far less optimal network parameters than those currently published on these data sets. Figure 10: Full Convolution DenseNet Architecture Full Convolution DenseNet uses DenseNet as its base encoder, and also stitches the encoder and decoder at each level in a manner similar to U-Net. Paper links: https://arxiv.org/abs/1611.09326 ▌E-Net and Link-Net In this article, we propose a new deep neural network architecture called ENet (efficient neural network) that is specifically created for tasks that require low latency operations. ENet is 18 times faster than current network models, 75 times less FLOPs, 79 times fewer parameters, and provides similar or even better accuracy. We conducted tests on the CamVid, Cityscapes, and SUN datasets, showing the results of comparisons with existing best practices, and the trade-offs between network accuracy and processing time. LinkNet can process images with a resolution of 1280x720 at 2fps and 19fps on the TX1 and Titan X, respectively. Figure 11: (Left) LinkNet Architecture, (Right) Encoder and Decoder Modules Used in LinkNet The LinkNet architecture is similar to a ladder network architecture in which the encoder feature map (transverse) and the decoder's upsampled feature map (vertical) are summed. It should also be noted that the decoder module contains relatively few parameters due to its channel reduction scheme. The feature map of size [H, W, n_channels] first obtains a feature map of size [H, W, n_channels / 4] through a 1*1 convolution kernel, and then uses deconvolution to change it to [2*H]. 2*W, n_channels / 4], and finally using a 1*1 convolution to make its size [2*H, 2*W, n_channels/2], so the decoder has fewer parameters. These networks can be segmented on an embedded GPU in real-time while achieving fairly close to optimal accuracy. Related links: https://arxiv.org/abs/1606.02147; Https://codeac29.github.io/projects/linknet/ ▌Mask R-CNN This method is called Mask R-CNN. Based on Faster R-CNN, a parallel branch of the prediction target mask is added on the basis of the existing bounding box recognition branch. Mask R-CNN is easy to train. It only adds a small overhead to the Faster R-CNN, running at 5fps. In addition, Mask R-CNN is easy to generalize to other tasks. For example, the same framework can be used for pose estimation. We achieved optimal results in all COCO Challenges, including instance segmentation, bounding box target detection, and human critical point detection. Without any use of skill, Mask R-CNN outperforms all existing single-model networks on every mission, including the winners of the COCO 2016 Challenge. Figure 12: Mask R-CNN Segmentation Process Original Faster-RCNN Architecture and Auxiliary Splitting Branch The Mask R-CNN architecture is quite simple. It is an extension of the popular Faster R-CNN architecture. It is based on the necessary modifications to perform semantic segmentation. Key features: Add auxiliary branches on Faster R-CNN to perform semantic segmentation. The RoIPool operation on each instance has been modified to RoIAlign, which avoids the spatial quantification of feature extraction because maintaining the spatial features at the highest resolution is important for semantic segmentation. Mask R-CNN combined with Feature Pyramid Networks (similar to PSPNet, which uses pyramid pooling for features) achieved optimal results on MS COCO datasets. At 2017-06-01, no work on Mask R-CNN was implemented on the network, and no benchmarks were performed on Pascal VOC, but its segmentation mask showed that it was very close to the real annotation. Paper links: https://arxiv.org/abs/1703.06870 ▌PSPNet In this paper, we use the context information collection based on different regions, and use our Pyramid Scene Parsing Network (PSPNet) to exploit our global context information capabilities through our pyramid pooling module. Our global a priori characterization yields good quality results in the scene resolution task, and PSPNet provides a better framework for pixel-level prediction. This method achieves optimal performance on different data sets. It first appeared in the 2016 ImageNet Scene Resolution Challenge PASCAL VOC 2012 benchmark and the Cityscapes benchmark. Figure 13: PSPNet Architecture Visualized space pyramid pooling using netscope Key features: PSPNet modifies the underlying ResNet architecture by introducing a hole convolution. Features are initially pooled and processed in the entire encoder network with the same resolution (1/4 of the original image input) until it reaches the space pooling module. . Introduce auxiliary losses in the middle layer of ResNet to optimize overall learning. The spatial pyramidal pooled aggregate global context at the top of the modified ResNet encoder. Figure 14: The picture shows the importance of global spatial contexts for semantic segmentation. It shows the relationship between field receptivity and size. In this example, the larger, more discriminating receptive field (blue) may be more important than the previous layer (orange) in refining the representation, which helps to resolve ambiguities. The PSPNet architecture currently has the best results in CityScapes, ADE20K, and Pascal VOC 2012. Paper links: https://arxiv.org/abs/1612.01105 ▌RefineNet RefineNet, a general-purpose multi-path optimization network, is proposed in this paper. It explicitly uses all the information available during the entire downsampling process and uses remote residual connections to achieve high-resolution predictions. In this way, fine-grained features in early convolutions can be used to directly refine deeper network layers that capture high-level semantic features. The various components of RefineNet use a residual connection that follows the idea of ​​identity mapping, which allows the network to perform effective end-to-end training. Figure 15: RefineNet Architecture Building RefineNet's Block-Residual Convolution Unit, Multi-Resolution Fusion, and Chain Residue Pooling RefineNet solves the problem of reduced spatial resolution in traditional convolutional networks and uses a very different approach from PSPNet (using computationally expensive hole convolutions). The proposed architecture iteratively pools features, uses special RefineNet modules to add different resolutions, and ultimately produces high-resolution segmented graphs. Key features: Using multi-resolution as input, the extracted features are fused together and passed to the next stage. Introducing chained residual pooling, background information can be obtained from a large image area. It effectively pools features through multiple window sizes, fuses these features using residual joins and learning weights. All feature fusions are performed using the sum (ResNet method) for end-to-end training. Using the residual layer of the normal ResNet, there is no calculation of a costly hole convolution. Paper links: https://arxiv.org/abs/1611.06612 G-FRNet In this paper, a Gated Feedback Refinement Network (G-FRNet) is proposed, which is an end-to-end deep learning framework for intensive tagging tasks that solves the limitations of existing methods. Initially, GFRNet made a rough prediction and then gradually refined the details by integrating the local and global context information effectively during the elaboration phase. We introduced a gating unit that forwards control information to filter ambiguities. Figure 16: G-FRNet Architecture Gated refinement unit Most of the above architectures rely on simple features from encoders to decoders, using splicing, de-pooling, or simple summation. However, in the encoder, it is not sure whether or not it is useful for segmentation from information corresponding to the upsampling feature map in the high-resolution (harder to distinguish) layer to the corresponding decoder. At each stage, the flow of information from the encoder to the decoder is controlled by using a gated refinement feedback unit, which helps the decoder to resolve ambiguities and form a more relevant gated space context. On the other hand, the experiments in this paper show that ResNet is a much better encoder than VGG16 in semantic segmentation tasks. This is something I could not find in previous papers. Paper link: http://~ywang/papers/cvpr17.pdf Semi-supervised semantic segmentation DecoupledNet In contrast to existing methods that use semantic segmentation as a single task based on region classification, our algorithm separates classification from segmentation and learns a separate network for each task. In this architecture, the tags associated with the image are identified through the classification network, and then the binary segmentation is performed on each of the identified tags in the segmentation network. It effectively reduces the search space for segmentation by using a specific class of activation maps obtained from the bridging layer. Figure 17: DecoupledNet Architecture This may be the first semi-supervised method for semantic segmentation using a full convolutional network. Key features: Separating the classification and segmentation tasks enables the pre-trained classification network to be plug and play. The bridging layer between the classification and segmentation networks generates a prominent class of feature maps (k-class), and then inputs the segmentation network to generate a binary segmentation map (k-class) However, this method splits the k class in an image and needs to be passed k times. Paper links: https://arxiv.org/abs/1506.04924 GAN-based methods Based on generating antagonism networks (GANs), we propose a semi-supervised framework that contains a generator network to provide additional training samples for multi-class classifiers as discriminators in the GAN framework, from K possible In the class, assign a tag y to the sample or mark it as a fake sample (extra class). To ensure that the images generated by GANs are of higher quality and to improve pixel classification, we extend the above framework by adding weak label data, that is, we provide class-level information to the generator. Paper links: https://arxiv.org/abs/1703.09695 Figure 18: Weak Supervision (Class-Level Label) GAN Figure 19: Semi-supervised GAN Data set Results Figure 20: Semantic Separation of Samples Generated by FCN-8s (using pytorch-semseg training) from Pascal VOC Validation Set Shenzhen Kate Technology Co., Ltd. , https://www.katevape.com