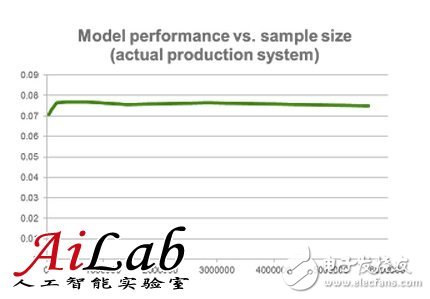
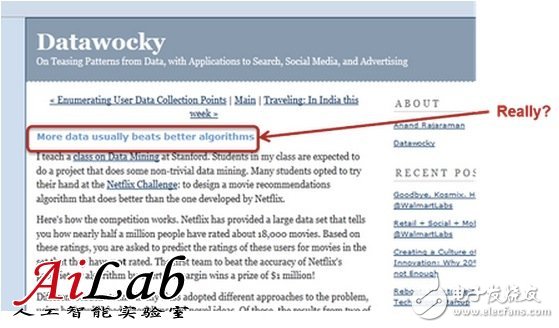
Is more data better than better algorithms in machine learning? For this question on Quora, Xavier Amatriain, director of engineering at Netflix, believes that adding more samples to the training set often does not improve the model. Performance, and if there is no reasonable way, the data will become noisy. He derived the final conclusions from Netflix's practical experience: What we need is a good way to help us understand how to interpret the data, the model, and the limitations of both, all for the best output. Is more data always better than better algorithms in machine learning? not like this. Sometimes more data is useful and sometimes it doesn't work. Defending the power of data, perhaps the most famous is Google Norbert, director of research and development, who claimed that "we don't have a better algorithm. We only have more data." This sentence is usually linked to the article "The Unreasonable EffecTIveness of Data", this article is also written by Norvig himself (although its source is placed in the IEEE toll area, but you should be able to find the original document in pdf format). A better model is to say that Norvig's quotations “all models are wrong, you will not need them anyway†are misquoted (click here to see the author clarify how he was misquoted). The role of Norvig et al. refers to the fact that in their articles, their views were long ago by Microsoft researchers Banko and Brill in a famous paper [2001] "Scaling to Very Very Large Corpora for Natural Language Disambigua Tion". References. In this paper, the author gives the following figure. The figure shows that for a given problem, the results of very different algorithms perform almost identically. However, adding more samples (words) to the training set can monotonically increase the accuracy of the model. Therefore, in the closed case, you may think that the algorithm is more important. Hmmm... not so fast. The fact is that Norvig's assertions and the papers of Banko and Brill are correct...in an environment. However, they are now mistakenly cited in environments that are completely different from the original environment. However, in order to understand why, we need to understand some technologies. (I'm not going to give you a complete machine-learning tutorial in this article. If you don't understand what I'm going to do next, read my answer to "How do I learn machine learning?" Variance or deviation? The basic idea is that there are two possible (and almost opposite) reasons why a model may perform poorly. In the first case, the model we use is too complicated for the amount of data we have. This is a situation that is known for high variance, which can lead to overfitting of the model. We know that we are facing a high variance problem when the training error is far below the test error. High variance can be solved by reducing the number of features. Yes, there is a way to increase the number of data points. So, what kind of model is Banko & Brill's point of view and Norvig's assertion can handle? Yes, the answer is correct: high variance. In both cases, the author devotes himself to the language model, where about every word in the vocabulary has characteristics. Compared to training samples, there are some models that have many characteristics. Therefore, they are very likely to overfit. Yes, in this case, adding more samples will bring a lot of help. However, in the opposite case, we may have a model that is too simple to explain the data we have. In this case, known as high deviation, adding more data will not help. See below for an actual tabulation of the system running at Netflix and its performance, and we add more training samples to it. Therefore, more data is not always helpful. As we have just seen, in many cases, adding more samples to our training set will not improve the performance of the model. Multi-feature rescue If you have followed my rhythm, so far you have completed homework to understand high variance and high deviation problems. You may think that I deliberately left something to discuss. Yes, high-bias models will not benefit from more training samples, but they are likely to benefit from more features. So, is this all about adding "more" data? OK, once again, it depends on the situation. For example, in the early days of the Netflix Prize, there was a blog post that addresses the use of additional features to comment. It was established by entrepreneurs and Stanford University professor Anand Rajaraman. This post explains how a student team can improve prediction accuracy by adding content features from the IMDB. In retrospect, it is easy to criticize the vulgar over-generalization of a single data point. What is more, the follow-up article mentioned that SVD is a "complex" algorithm and is not worth trying, because it limits the ability to expand more features. Apparently, Anand's students did not win the Netflix Prize, and they may now realize that SVD plays an important role in the winning entries. In fact, many teams later showed that adding content features from IMDB, etc., to an optimization algorithm hardly improves. Some members of the Gravity team, one of the best contenders for the Netflix Prize, published a detailed paper demonstrating that there has been no improvement in adding these content-based features to highly optimized collaborative filtering matrix decomposition. This paper is entitled "Recommending New Movies: Even a Few RaTIngs Are More Valuable Than Metadata". For the sake of fairness, the title of the paper is also an over-generalization. Content-based features (or generally different features) can improve accuracy in many situations. However, you understand what I mean: More data doesn't always help. Better data! = More data In my opinion, it is important to point out that better data is always better. There is no objection to this. So any effort to "improve" your data directly is always a good investment. The problem is that better data does not mean more data. In fact, sometimes this may mean less! Thinking about data cleanup or outlier removal is a trivial explanation of my point of view. However, there are many other more subtle examples. For example, I have seen people invest a lot of energy in Matrix FactorizaTIon, and the truth is that they may be recognized by sampling data and getting very similar results. In fact, the right way to do some form of smart population sampling (for example, using stratified sampling) can give you better results than using an entire unfiltered data set. The end of the scientific method? Of course, whenever there is a fierce debate about possible paradigms, there will be people like Malcolm Gladwell and Chris Anderson making a living without even thinking hard (don't get me wrong. I'm a fan of both of them. I Read many of their books). In this case, Anderson picked up some of Norvig's comments and mistakenly cited it in an article entitled: "The End of Theory: The Data Deluge Makes the Scientific Method Obsolete." This article describes several examples of how rich data can help people and businesses make decisions without even having to understand the meaning of the data itself. As Andrig himself pointed out in his rebuttal, Anderson has several points that are correct but difficult to achieve. And the result is a set of false statements, starting with the headline: Massive data does not eliminate scientific methods. I think this is just the opposite. There is no reasonable method for data = noise So, I was trying to make the big data revolution just hype? impossible. There is more data, whether it is more examples of samples or more features, is a blessing. The availability of data makes more and better insights and applications possible. More data does bring better methods. More importantly, it needs a better way. To sum up, we should ignore the oversimplified opinions, which promote the uselessness of theories or models, or the possibility of success of data in other aspects. As much data as necessary is needed, so good models and theories are needed to explain them. But, in general, what we need is a good way to help us understand how to interpret the data, the model, and the limitations of both, all for the best output. In other words, data is important, but without a reasonable method, the data will become noise. Medical Aid Equipment Wire Harness
The wiring harness for medical rescue equipment refers to the wiring harness applied to various medical rescue equipment. Emergency medical equipment, that is, the medical equipment used in emergency treatment, refers to the emergency medical equipment used by the rescuer when any accident or emergency occurs.
We produce a large number of Medical Cable Assembly, including Ventilator Wire Harness, Medical Defibrillator Wire Harness and Medical Aid Equipment Wire Harness .
Medical Aid Equipment Wire Harness,Medical Equipment Wire Harness,Medical Custom Cable Harness,Medical Aid Equipment Wire Harness For Sale Kable-X Technology (Suzhou) Co., Ltd , https://www.kable-x-tech.com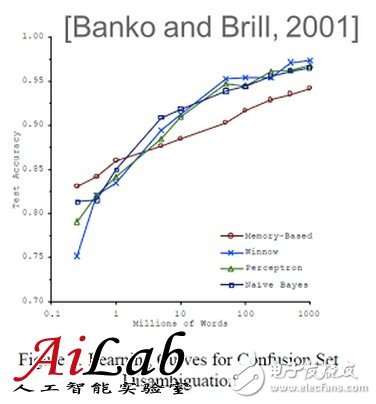



Before arrival, in accordance with the principles of medical care, use on-site applicable medical equipment to temporarily and appropriately perform preliminary rescue and care for the wounded and sick.
Kable-X provides various connecting harness components for medical device maple equipment. These wiring harness not only meet the needs of signal transmission and high-voltage contacts, electrical appliances and machinery, but also provide reliable and stable quality for customers' special application requirements, most of which are used for Computer tomography equipment, movable auxiliary equipment, solutions for increasing demand, medical electronic beds, rotatable chairs and wheelchair controllers.
