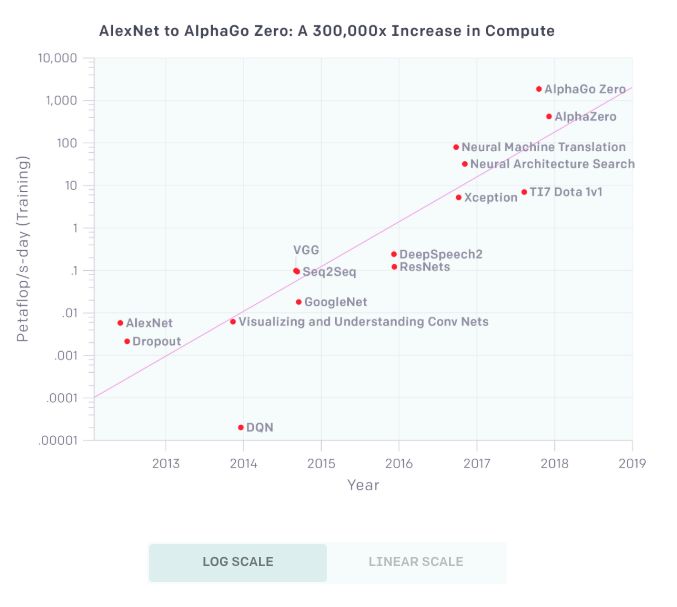
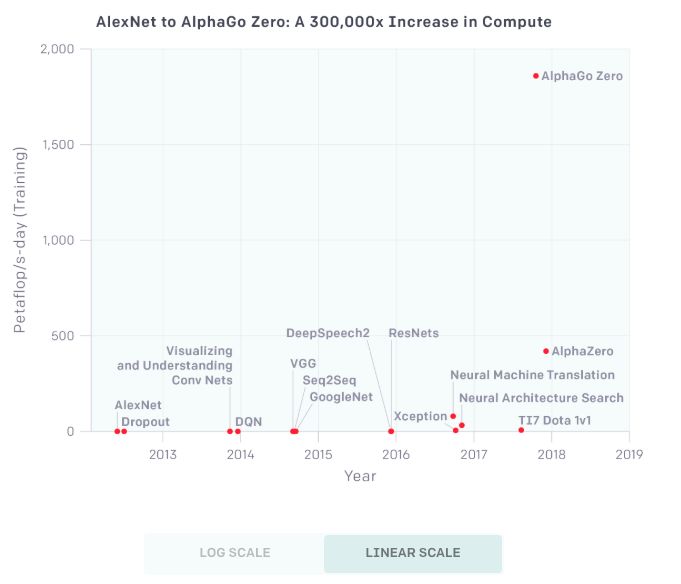
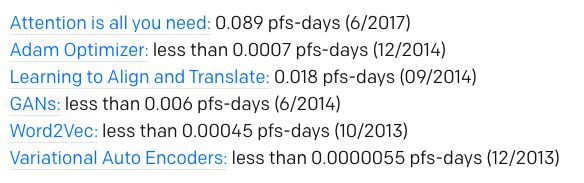
Today, OpenAI released an analysis report on the growth trend of AI computing capabilities. The report shows that since 2012, the computing power used in AI training has doubled every 3.5 months. Since 2012, this indicator has grown. 300,000 times more. There are three factors driving the development of artificial intelligence: algorithmic innovation, data (which can be supervised data or interactive environments), and the amount of computation that can be used for training. Algorithmic innovations and data are difficult to track, but the amount of computation is quantifiable, which provides an opportunity to measure the speed of progress of artificial intelligence. Of course, the use of large-scale calculations sometimes exposes the shortcomings of current algorithms. But at least in many areas of the current world, more calculations seem to foresee better performance, and computational power often complements algorithmic advancements. For "computational power," we know the famous "Moore's law": the number of components that can be accommodated on integrated circuits will double approximately every 18-24 months, and the performance will also double. . Today, OpenAI, a non-profit AI research organization, published an analysis report on "AI and Calculations". The report shows: Since 2012, the computing power used in the largest AI training operations has grown exponentially, doubling every 3.5 months (in contrast, the Moore's Law doubling time is 18 months). Since 2012, this indicator has grown more than 300,000 times (if it takes 18 months to double, it can only increase by 12 times). The increase in computing power has been a key element of AI's progress, so as long as this trend continues, it will be worthwhile to prepare ourselves for the impact of AI systems far beyond today's capabilities. "Moore's Law" Calculated by AI: Doubled in 3.43 Months For this analysis, we believe that the relevant numbers are not the speed of a single GPU, nor the largest data center capacity, but the amount of computation used to train a single model—this is the number that is most relevant to how powerful the best model is. . Because parallelism (hardware and algorithms) limits the size of the model and the degree to which it can be effectively trained, the amount of computation for each model varies greatly from the total number of calculations. Of course, a number of important breakthroughs have still been made with a small amount of calculations, but this analysis only covers computational power. Log Scale The above chart shows the total number of calculations used to train some well-known models and get better results. The unit is petaflop/s-days, uses a lot of time calculations, and provides enough information to estimate the calculations used. 1 petaflop/s-days (pfs-day) refers to 10 times of 10 neural network operations per second, or a total of 10 20 operations. The unit of this compute-time is for convenience, similar to the energy measurement unit kilowatt hour (kW-hr). We do not measure the peak theoretical FLOPS of the hardware, but try to estimate the number of actual operations performed. We treat addition and multiplication as separate operations, adding any addition or multiplication as an operation, regardless of the precision of the values ​​(thus "FLOP" is less appropriate), and we ignore the integration model. An example calculation of this chart is provided in the appendix of this article. Linear Scale The results show that the doubling time of the best-fit line is 3.43 months. This trend increases at a rate of 10 times per year. This is partly due to custom hardware that allows more operations per second at a certain price (GPU and TPU). But the more important factor is that researchers are constantly looking for new ways to use more chips in parallel and are willing to pay more. 4 times From the above chart, we can roughly divide it into 4 eras: Before 2012: Using GPUs for machine learning is not common, so any results in the chart are difficult to achieve. 2012 to 2014: Architectures that are trained on multiple GPUs are not common, so most results use 1-8 GPUs, performance is 1-2 TFLOPS, and a total of 0.001-0.1 pfs-days. 2014 to 2016: Large-scale use of 10-100 GPUs with a performance of 5-10 TFLOPS and a result of 0.1-10 pfs-days. The diminishing returns of data parallelism means that the value of larger-scale training operations is limited. 2016 to 2017: Methods that allow for greater algorithmic parallelism, such as large batch sizes, architectural searches and expert iterations, and specialized hardware such as TPUs, faster interconnections, etc., greatly increase these limits , at least for some applications. AlphaGoZero/AlphaZero is one of the most significant examples of large-scale algorithm parallelism, but many other such large-scale applications are now algorithmically viable and may already be used in production environments. This trend will continue and we must walk in front of it We have many reasons to believe that the trends shown in the chart can continue. Many hardware startups are developing AI-specific chips, and some companies claim that they will be able to significantly increase FLOPS / Watt in the next 1-2 years (which is closely related to economic costs). The same number of operations can also be accomplished by simply reconfiguring the hardware to reduce the economic cost. In terms of parallelism, many of the recent algorithmic innovations described above can be combined in principle—for example, architectural search algorithms and massively parallel SGD. On the other hand, the cost will eventually limit the parallelism of this trend, and physics will also limit the efficiency of the chip. We believe that the current hardware cost for the largest training operation is only a few million dollars (although the amortization cost is much lower). But most current neural network calculations are still used for reasoning (deployment) rather than training, which means companies can repurpose or buy more chips for training. Therefore, if there are enough economic incentives, we can see more massive parallel training, so that this trend lasts for several years. The total hardware budget of the world amounts to 1 trillion US dollars each year, so the absolute limit is still far. In general, taking into account the aforementioned data, precedents for calculating index trends, research on machine learning specific hardware, and economic incentives, we believe this trend will continue. How long this trend will last and what will continue to happen will be insufficient to predict with past trends. However, even if the potential for rapid growth in computing power is within a reasonable range, it also means that it is crucial to address the security and malicious use of AI today. Vision is crucial for responsible policy development and responsible technological development. We must go ahead of these trends rather than react to trends. Methods and latest results Two methods are used to generate these data points. When we have enough information, we calculate the number of FLOPs (summed and multiplied) directly in the schema described in each training example and multiply the total number of forward and backward channels during training. When we didn't have enough information to calculate the FLOP directly, we looked at the GPU's training time and the total number of GPUs used and assumed the usage efficiency (usually 0.33). For most papers, we can use the first method, but for a few papers, we rely on the second method, and for consistency testing, we try to calculate these two indicators as much as possible. In most cases, we also confirmed this to the author. The calculation is not accurate, but our goal is to be correct within the range of 2-3 times. We provide some sample calculations below. Case 1: Counting Model Operations This method is particularly easy to use when the author gives an operand for forward pass, as in the Resnet paper (especially the Resnet-151 model): These operations can also calculate the known model architecture programmatically in some deep learning frameworks, or we can simply calculate operations manually. If a paper provides enough information to calculate, it will be very accurate, but in some cases, the paper does not contain all the necessary information, and the author cannot disclose it. Method 2 example: GPU time If we can't calculate directly, we can look at how many GPUs have been trained and use reasonable guesses on GPU utilization to try to estimate the number of operations performed. We emphasize that here we do not calculate the peak theory FLOPS, but use the hypothetical fraction of the theoretical FLOPS to try to guess the actual FLOPS. Based on our own experience, we usually assume that the GPU utilization is 33% and the CPU utilization is 17%, unless we have more specific information (for example, we have to communicate with the author or do it on OpenAI). For example, in AlexNet's paper it was mentioned that "it takes 5 to 6 days to train our network on two GTX 580 3 GB GPUs." Under our assumptions, this means that the total calculation: This method is more approximate and can be easily reduced by 2 or more. Our goal is only to estimate the order of magnitude. In practice, when both methods are available, they are usually arranged very well (for AlexNet, we can also calculate the operation directly. In the GPU time method, the results are 0.0054 pfs-days and 0.0058 pfs, respectively. -days. The latest results using the right amount of calculations Large-scale computing is certainly not a requirement to produce important results. Many of the recent noteworthy results use only the right amount of calculations. The following are some examples of results using a moderate calculation that provide enough information to estimate their calculations. We did not use multiple methods to estimate the results of these models. For the upper limit, we made a conservative estimate of any missing information and therefore they have greater overall uncertainty. These estimates are not very important to our quantitative analysis, but we still think they are interesting and worth sharing: Small Gear Motor,Customized Dc Motor,Customized Dc Gear Motor,Dc Permanent Magnet Motor NingBo BeiLun HengFeng Electromotor Manufacture Co.,Ltd. , https://www.hengfengmotor.com